This function trains a Convolutional Neural Network (CNN) on the provided input data X and the target data Y using the specified architecture, loss function, and optimizer.
Usage
cnn(
X,
Y = NULL,
architecture,
loss = c("mse", "mae", "softmax", "cross-entropy", "gaussian", "binomial", "poisson",
"mvp", "nbinom", "multinomial", "clogit"),
optimizer = c("sgd", "adam", "adadelta", "adagrad", "rmsprop", "rprop"),
lr = 0.01,
alpha = 0.5,
lambda = 0,
validation = 0,
batchsize = 32L,
burnin = 30,
shuffle = TRUE,
epochs = 100,
early_stopping = NULL,
lr_scheduler = NULL,
custom_parameters = NULL,
device = c("cpu", "cuda", "mps"),
plot = TRUE,
verbose = TRUE
)Arguments
- X
An array of input data with a minimum of 3 and a maximum of 5 dimensions. The first dimension represents the samples, the second dimension represents the channels, and the third to fifth dimensions represent the input dimensions.
- Y
The target data. It can be a factor, numeric vector, or a numeric or logical matrix.
- architecture
An object of class 'citoarchitecture'. See
create_architecturefor more information.- loss
The loss function to be used. Options include "mse", "mae", "softmax", "cross-entropy", "gaussian", "binomial", "poisson", "nbinom", "mvp", "multinomial", and "clogit". You can also specify your own loss function. See Details for more information. Default is "mse".
- optimizer
The optimizer to be used. Options include "sgd", "adam", "adadelta", "adagrad", "rmsprop", and "rprop". See
config_optimizerfor further adjustments to the optimizer. Default is "sgd".- lr
Learning rate for the optimizer. Default is 0.01.
- alpha
Alpha value for L1/L2 regularization. Default is 0.5.
- lambda
Lambda value for L1/L2 regularization. Default is 0.0.
- validation
Proportion of the data to be used for validation. Default is 0.0.
- batchsize
Batch size for training. Default is 32.
- burnin
Number of epochs after which the training stops if the loss is still above the base loss. Default is 30.
- shuffle
Whether to shuffle the data before each epoch. Default is TRUE.
- epochs
Number of epochs to train the model. Default is 100.
- early_stopping
Number of epochs with no improvement after which training will be stopped. Default is NULL.
- lr_scheduler
Learning rate scheduler. See
config_lr_schedulerfor creating a learning rate scheduler. Default is NULL.- custom_parameters
Parameters for the custom loss function. See the vignette for an example. Default is NULL.
- device
Device to be used for training. Options are "cpu", "cuda", and "mps". Default is "cpu".
- plot
Whether to plot the training progress. Default is TRUE.
- verbose
Whether to print detailed training progress. Default is TRUE.
Value
An S3 object of class "citocnn" is returned. It is a list containing everything there is to know about the model and its training process.
The list consists of the following attributes:
- net
An object of class "nn_sequential" "nn_module", originates from the torch package and represents the core object of this workflow.
- call
The original function call.
- loss
A list which contains relevant information for the target variable and the used loss function.
- data
Contains the data used for the training of the model.
- base_loss
The loss of the intercept-only model.
- weights
List of parameters (weights and biases) of the models from the best and the last training epoch.
- buffers
List of buffers (e.g. running mean and variance of batch normalization layers) of the models from the best and the last training epoch.
- use_model_epoch
Integer, defines whether the model from the best (= 1) or the last (= 2) training epoch should be used for prediction.
- loaded_model_epoch
Integer, shows whether the parameters and buffers of the model from the best (= 1) or the last (= 2) training epoch are currently loaded in
net.- model_properties
A list of properties, that define the architecture of the model.
- training_properties
A list of all the training parameters used the last time the model was trained.
- losses
A data.frame containing training and validation losses of each epoch.
Convolutional Neural Networks:
Convolutional Neural Networks (CNNs) are a specialized type of neural network designed for processing structured data, such as images. The key components of a CNN are convolutional layers, pooling layers and fully-connected (linear) layers:
Convolutional layers are the core building blocks of CNNs. They consist of filters (also called kernels), which are small, learnable matrices. These filters slide over the input data to perform element-wise multiplication, producing feature maps that capture local patterns and features. Multiple filters are used to detect different features in parallel. They help the network learn hierarchical representations of the input data by capturing low-level features (edges, textures) and gradually combining them (in subsequent convolutional layers) to form higher-level features.
Pooling layers reduce the size of the feature maps created by convolutional layers, while retaining important information. A common type is max pooling, which keeps the highest value in a region, simplifying the data while preserving essential features.
Fully-connected (linear) layers connect every neuron in one layer to every neuron in the next layer. These layers are found at the end of the network and are responsible for combining high-level features to make final predictions.
Loss functions / Likelihoods
We support loss functions and likelihoods for different tasks:
| Name | Explanation | Example / Task |
| mse | mean squared error | Regression, predicting continuous values |
| mae | mean absolute error | Regression, predicting continuous values |
| softmax | categorical cross entropy | Multi-class, species classification |
| cross-entropy | categorical cross entropy | Multi-class, species classification |
| gaussian | Normal likelihood | Regression, residual error is also estimated (similar to stats::lm()) |
| binomial | Binomial likelihood | Classification/Logistic regression, mortality |
| poisson | Poisson likelihood | Regression, count data, e.g. species abundances |
| nbinom | Negative binomial likelihood | Regression, count data with dispersion parameter |
| mvp | multivariate probit model | joint species distribution model, multi species (presence absence) |
| multinomial | Multinomial likelihood | step selection in animal movement models |
| clogit | conditional binomial | step selection in animal movement models |
Training and convergence of neural networks
Ensuring convergence can be tricky when training neural networks. Their training is sensitive to a combination of the learning rate (how much the weights are updated in each optimization step), the batch size (a random subset of the data is used in each optimization step), and the number of epochs (number of optimization steps). Typically, the learning rate should be decreased with the size of the neural networks (amount of learnable parameters). We provide a baseline loss (intercept only model) that can give hints about an appropriate learning rate:
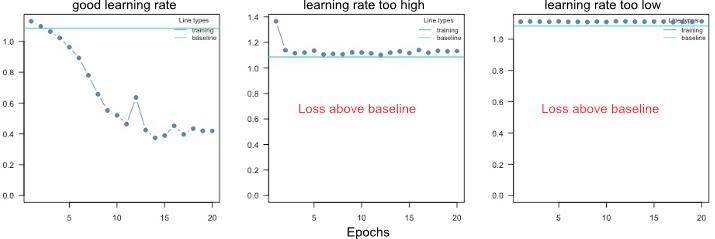
If the training loss of the model doesn't fall below the baseline loss, the learning rate is either too high or too low. If this happens, try higher and lower learning rates.
A common strategy is to try (manually) a few different learning rates to see if the learning rate is on the right scale.
See the troubleshooting vignette (vignette("B-Training_neural_networks")) for more help on training and debugging neural networks.
Finding the right architecture
As with the learning rate, there is no definitive guide to choosing the right architecture for the right task. However, there are some general rules/recommendations: In general, wider, and deeper neural networks can improve generalization - but this is a double-edged sword because it also increases the risk of overfitting. So, if you increase the width and depth of the network, you should also add regularization (e.g., by increasing the lambda parameter, which corresponds to the regularization strength). Furthermore, in Pichler & Hartig, 2023, we investigated the effects of the hyperparameters on the prediction performance as a function of the data size. For example, we found that the selu activation function outperforms relu for small data sizes (<100 observations).
We recommend starting with moderate sizes (like the defaults), and if the model doesn't generalize/converge, try larger networks along with a regularization that helps minimize the risk of overfitting (see vignette("B-Training_neural_networks") ).
Overfitting
Overfitting means that the model fits the training data well, but generalizes poorly to new observations. We can use the validation argument to detect overfitting. If the validation loss starts to increase again at a certain point, it often means that the models are starting to overfit your training data:
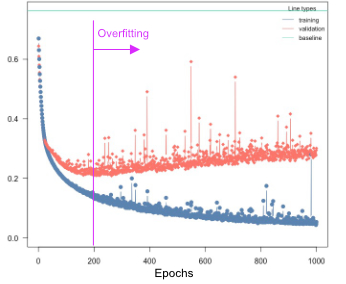
Solutions:
Re-train with epochs = point where model started to overfit
Early stopping, stop training when model starts to overfit, can be specified using the
early_stopping=…argumentUse regularization (dropout or elastic-net, see next section)
Regularization
Elastic Net regularization combines the strengths of L1 (Lasso) and L2 (Ridge) regularization. It introduces a penalty term that encourages sparse weight values while maintaining overall weight shrinkage. By controlling the sparsity of the learned model, Elastic Net regularization helps avoid overfitting while allowing for meaningful feature selection. We advise using elastic net (e.g. lambda = 0.001 and alpha = 0.2).
Dropout regularization helps prevent overfitting by randomly disabling a portion of neurons during training. This technique encourages the network to learn more robust and generalized representations, as it prevents individual neurons from relying too heavily on specific input patterns. Dropout has been widely adopted as a simple yet effective regularization method in deep learning.
By utilizing these regularization methods in your neural network training with the cito package, you can improve generalization performance and enhance the network's ability to handle unseen data. These techniques act as valuable tools in mitigating overfitting and promoting more robust and reliable model performance.
Custom Optimizer and Learning Rate Schedulers
When training a network, you have the flexibility to customize the optimizer settings and learning rate scheduler to optimize the learning process. In the cito package, you can initialize these configurations using the config_lr_scheduler and config_optimizer functions.
config_lr_scheduler allows you to define a specific learning rate scheduler that controls how the learning rate changes over time during training. This is beneficial in scenarios where you want to adaptively adjust the learning rate to improve convergence or avoid getting stuck in local optima.
Similarly, the config_optimizer function enables you to specify the optimizer for your network. Different optimizers, such as stochastic gradient descent (SGD), Adam, or RMSprop, offer various strategies for updating the network's weights and biases during training. Choosing the right optimizer can significantly impact the training process and the final performance of your neural network.
Training on graphic cards
If you have an NVIDIA CUDA-enabled device and have installed the CUDA toolkit version 11.3 and cuDNN 8.4, you can take advantage of GPU acceleration for training your neural networks. It is crucial to have these specific versions installed, as other versions may not be compatible. For detailed installation instructions and more information on utilizing GPUs for training, please refer to the mlverse: 'torch' documentation.
Note: GPU training is optional, and the package can still be used for training on CPU even without CUDA and cuDNN installations.
Examples
# \donttest{
if(torch::torch_is_installed()){
library(cito)
# Example workflow in cito
device <- ifelse(torch::cuda_is_available(), "cuda", "cpu")
## Data
### We generate our own data:
### 320 images (3x50x50) of either rectangles or ellipsoids
shapes <- cito:::simulate_shapes(n=320, size=50, channels=3)
X <- shapes$data
Y <- shapes$labels
## Architecture
### Declare the architecture of the CNN
### Note that the output layer is added automatically by cnn()
architecture <- create_architecture(conv(5), maxPool(), conv(5), maxPool(), linear(10))
## Build and train network
### softmax is used for classification
cnn.fit <- cnn(X, Y, architecture, loss = "softmax", epochs = 50, validation = 0.1, lr = 0.05, device=device)
## The training loss is below the baseline loss but at the end of the
## training the loss was still decreasing, so continue training for another 50
## epochs
cnn.fit <- continue_training(cnn.fit, epochs = 50)
# Structure of Neural Network
print(cnn.fit)
# Plot Neural Network
plot(cnn.fit)
## Convergence can be tested via the analyze_training function
analyze_training(cnn.fit)
## Transfer learning
### With the transfer() function we can use predefined architectures with pretrained weights
transfer_architecture <- create_architecture(transfer("resnet18"))
resnet <- cnn(X, Y, transfer_architecture, loss = "softmax",
epochs = 10, validation = 0.1, lr = 0.05, device=device)
print(resnet)
plot(resnet)
}
#> Error in match.arg(tolower(optimizer), choices = c("sgd", "adam", "adadelta", "adagrad", "rmsprop", "rprop", "ignite_adam")): 'arg' must be of length 1
# }