Continues training of a model generated with dnn or cnn for additional epochs.
Source: R/continue_training.R
continue_training.RdIf the training/validation loss is still decreasing at the end of the training, it is often a sign that the NN has not yet converged. You can use this function to continue training instead of re-training the entire model.
Usage
continue_training(model, ...)
# S3 method for class 'citodnn'
continue_training(
model,
epochs = 32,
data = NULL,
device = NULL,
verbose = TRUE,
changed_params = NULL,
init_optimizer = TRUE,
...
)
# S3 method for class 'citodnnBootstrap'
continue_training(
model,
epochs = 32,
data = NULL,
device = NULL,
verbose = TRUE,
changed_params = NULL,
parallel = FALSE,
init_optimizer = TRUE,
...
)
# S3 method for class 'citocnn'
continue_training(
model,
epochs = 32,
X = NULL,
Y = NULL,
device = NULL,
verbose = TRUE,
changed_params = NULL,
init_optimizer = TRUE,
...
)Arguments
- model
- ...
class-specific arguments
- epochs
additional epochs the training should continue for
- data
matrix or data.frame. If not provided data from original training will be used
- device
can be used to overwrite device used in previous training
- verbose
print training and validation loss of epochs
- changed_params
list of arguments to change compared to original training setup, see
dnnwhich parameter can be changed- init_optimizer
re-initialize optimizer or not
- parallel
train bootstrapped model in parallel
- X
array. If not provided X from original training will be used
- Y
vector, factor, numerical matrix or logical matrix. If not provided Y from original training will be used
Examples
# \donttest{
if(torch::torch_is_installed()){
library(cito)
set.seed(222)
validation_set<- sample(c(1:nrow(datasets::iris)),25)
# Build and train Network
nn.fit<- dnn(Sepal.Length~., data = datasets::iris[-validation_set,], epochs = 32)
# continue training for another 32 epochs
nn.fit<- continue_training(nn.fit,epochs = 32)
# Use model on validation set
predictions <- predict(nn.fit, iris[validation_set,])
}
#> Loss at epoch 1: 8.499764, lr: 0.01000
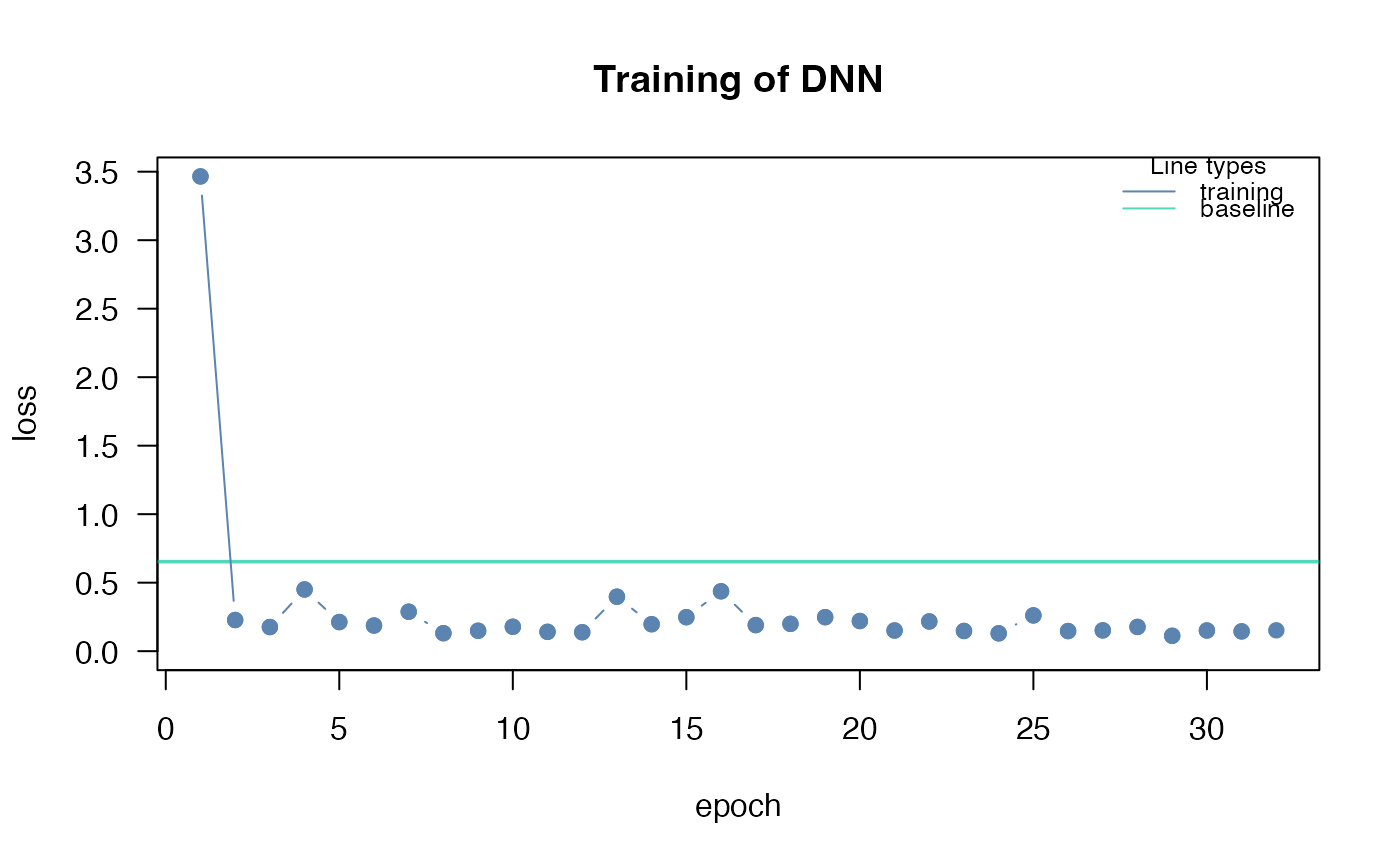 #> Loss at epoch 2: 0.155589, lr: 0.01000
#> Loss at epoch 3: 0.157004, lr: 0.01000
#> Loss at epoch 4: 0.143644, lr: 0.01000
#> Loss at epoch 5: 0.231614, lr: 0.01000
#> Loss at epoch 6: 0.158015, lr: 0.01000
#> Loss at epoch 7: 0.164213, lr: 0.01000
#> Loss at epoch 8: 0.210553, lr: 0.01000
#> Loss at epoch 9: 0.196251, lr: 0.01000
#> Loss at epoch 10: 0.155395, lr: 0.01000
#> Loss at epoch 11: 0.170208, lr: 0.01000
#> Loss at epoch 12: 0.157750, lr: 0.01000
#> Loss at epoch 13: 0.144073, lr: 0.01000
#> Loss at epoch 14: 0.158020, lr: 0.01000
#> Loss at epoch 15: 0.235408, lr: 0.01000
#> Loss at epoch 16: 0.154042, lr: 0.01000
#> Loss at epoch 17: 0.283179, lr: 0.01000
#> Loss at epoch 18: 0.137547, lr: 0.01000
#> Loss at epoch 19: 0.152476, lr: 0.01000
#> Loss at epoch 20: 0.204473, lr: 0.01000
#> Loss at epoch 21: 0.142053, lr: 0.01000
#> Loss at epoch 22: 0.228056, lr: 0.01000
#> Loss at epoch 23: 0.168625, lr: 0.01000
#> Loss at epoch 24: 0.282815, lr: 0.01000
#> Loss at epoch 25: 0.201953, lr: 0.01000
#> Loss at epoch 26: 0.190323, lr: 0.01000
#> Loss at epoch 27: 0.127644, lr: 0.01000
#> Loss at epoch 28: 0.184540, lr: 0.01000
#> Loss at epoch 29: 0.167853, lr: 0.01000
#> Loss at epoch 30: 0.138815, lr: 0.01000
#> Loss at epoch 31: 0.155092, lr: 0.01000
#> Loss at epoch 32: 0.165073, lr: 0.01000
#> Loss at epoch 33: 0.185073, lr: 0.01000
#> Loss at epoch 2: 0.155589, lr: 0.01000
#> Loss at epoch 3: 0.157004, lr: 0.01000
#> Loss at epoch 4: 0.143644, lr: 0.01000
#> Loss at epoch 5: 0.231614, lr: 0.01000
#> Loss at epoch 6: 0.158015, lr: 0.01000
#> Loss at epoch 7: 0.164213, lr: 0.01000
#> Loss at epoch 8: 0.210553, lr: 0.01000
#> Loss at epoch 9: 0.196251, lr: 0.01000
#> Loss at epoch 10: 0.155395, lr: 0.01000
#> Loss at epoch 11: 0.170208, lr: 0.01000
#> Loss at epoch 12: 0.157750, lr: 0.01000
#> Loss at epoch 13: 0.144073, lr: 0.01000
#> Loss at epoch 14: 0.158020, lr: 0.01000
#> Loss at epoch 15: 0.235408, lr: 0.01000
#> Loss at epoch 16: 0.154042, lr: 0.01000
#> Loss at epoch 17: 0.283179, lr: 0.01000
#> Loss at epoch 18: 0.137547, lr: 0.01000
#> Loss at epoch 19: 0.152476, lr: 0.01000
#> Loss at epoch 20: 0.204473, lr: 0.01000
#> Loss at epoch 21: 0.142053, lr: 0.01000
#> Loss at epoch 22: 0.228056, lr: 0.01000
#> Loss at epoch 23: 0.168625, lr: 0.01000
#> Loss at epoch 24: 0.282815, lr: 0.01000
#> Loss at epoch 25: 0.201953, lr: 0.01000
#> Loss at epoch 26: 0.190323, lr: 0.01000
#> Loss at epoch 27: 0.127644, lr: 0.01000
#> Loss at epoch 28: 0.184540, lr: 0.01000
#> Loss at epoch 29: 0.167853, lr: 0.01000
#> Loss at epoch 30: 0.138815, lr: 0.01000
#> Loss at epoch 31: 0.155092, lr: 0.01000
#> Loss at epoch 32: 0.165073, lr: 0.01000
#> Loss at epoch 33: 0.185073, lr: 0.01000
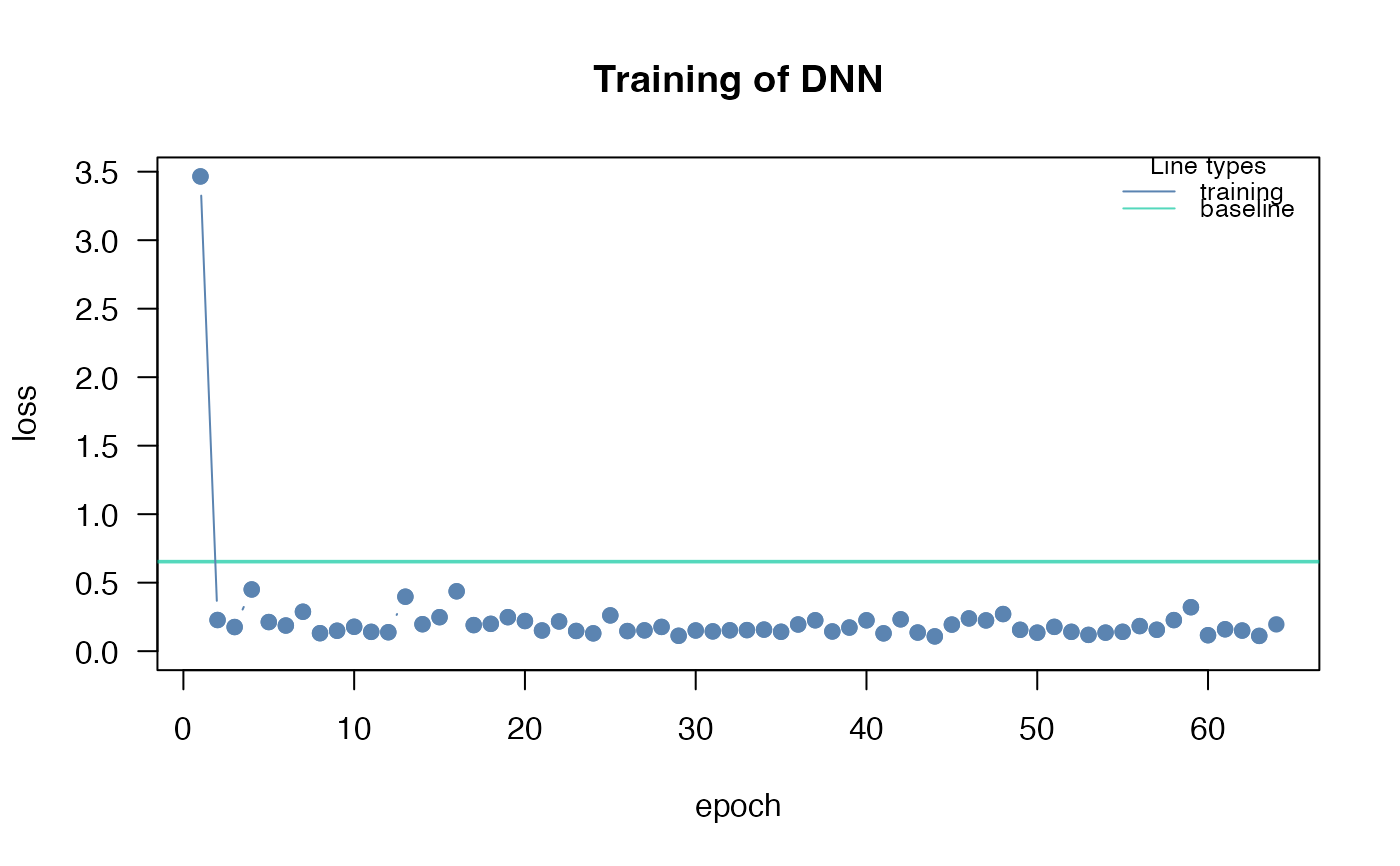 #> Loss at epoch 34: 0.133962, lr: 0.01000
#> Loss at epoch 35: 0.171664, lr: 0.01000
#> Loss at epoch 36: 0.163689, lr: 0.01000
#> Loss at epoch 37: 0.152154, lr: 0.01000
#> Loss at epoch 38: 0.169949, lr: 0.01000
#> Loss at epoch 39: 0.125309, lr: 0.01000
#> Loss at epoch 40: 0.167960, lr: 0.01000
#> Loss at epoch 41: 0.144890, lr: 0.01000
#> Loss at epoch 42: 0.205447, lr: 0.01000
#> Loss at epoch 43: 0.133132, lr: 0.01000
#> Loss at epoch 44: 0.149254, lr: 0.01000
#> Loss at epoch 45: 0.166839, lr: 0.01000
#> Loss at epoch 46: 0.132563, lr: 0.01000
#> Loss at epoch 47: 0.130921, lr: 0.01000
#> Loss at epoch 48: 0.133465, lr: 0.01000
#> Loss at epoch 49: 0.128637, lr: 0.01000
#> Loss at epoch 50: 0.207680, lr: 0.01000
#> Loss at epoch 51: 0.172898, lr: 0.01000
#> Loss at epoch 52: 0.256572, lr: 0.01000
#> Loss at epoch 53: 0.126001, lr: 0.01000
#> Loss at epoch 54: 0.204715, lr: 0.01000
#> Loss at epoch 55: 0.130464, lr: 0.01000
#> Loss at epoch 56: 0.125086, lr: 0.01000
#> Loss at epoch 57: 0.194425, lr: 0.01000
#> Loss at epoch 58: 0.174518, lr: 0.01000
#> Loss at epoch 59: 0.135576, lr: 0.01000
#> Loss at epoch 60: 0.145873, lr: 0.01000
#> Loss at epoch 61: 0.173474, lr: 0.01000
#> Loss at epoch 62: 0.115937, lr: 0.01000
#> Loss at epoch 63: 0.294653, lr: 0.01000
#> Loss at epoch 64: 0.153009, lr: 0.01000
# }
#> Loss at epoch 34: 0.133962, lr: 0.01000
#> Loss at epoch 35: 0.171664, lr: 0.01000
#> Loss at epoch 36: 0.163689, lr: 0.01000
#> Loss at epoch 37: 0.152154, lr: 0.01000
#> Loss at epoch 38: 0.169949, lr: 0.01000
#> Loss at epoch 39: 0.125309, lr: 0.01000
#> Loss at epoch 40: 0.167960, lr: 0.01000
#> Loss at epoch 41: 0.144890, lr: 0.01000
#> Loss at epoch 42: 0.205447, lr: 0.01000
#> Loss at epoch 43: 0.133132, lr: 0.01000
#> Loss at epoch 44: 0.149254, lr: 0.01000
#> Loss at epoch 45: 0.166839, lr: 0.01000
#> Loss at epoch 46: 0.132563, lr: 0.01000
#> Loss at epoch 47: 0.130921, lr: 0.01000
#> Loss at epoch 48: 0.133465, lr: 0.01000
#> Loss at epoch 49: 0.128637, lr: 0.01000
#> Loss at epoch 50: 0.207680, lr: 0.01000
#> Loss at epoch 51: 0.172898, lr: 0.01000
#> Loss at epoch 52: 0.256572, lr: 0.01000
#> Loss at epoch 53: 0.126001, lr: 0.01000
#> Loss at epoch 54: 0.204715, lr: 0.01000
#> Loss at epoch 55: 0.130464, lr: 0.01000
#> Loss at epoch 56: 0.125086, lr: 0.01000
#> Loss at epoch 57: 0.194425, lr: 0.01000
#> Loss at epoch 58: 0.174518, lr: 0.01000
#> Loss at epoch 59: 0.135576, lr: 0.01000
#> Loss at epoch 60: 0.145873, lr: 0.01000
#> Loss at epoch 61: 0.173474, lr: 0.01000
#> Loss at epoch 62: 0.115937, lr: 0.01000
#> Loss at epoch 63: 0.294653, lr: 0.01000
#> Loss at epoch 64: 0.153009, lr: 0.01000
# }