Training neural networks
Maximilian Pichler
2024-03-06
Source:vignettes/B-Training_neural_networks.Rmd
B-Training_neural_networks.RmdAbstract
This vignette helps to address certain problems that occur when training neural networks (NN) and gives hints on how to increase the likelihood of their convergence.Possible issues
-
Convergence issues, (often because of the learning rate), training loss above baseline loss:
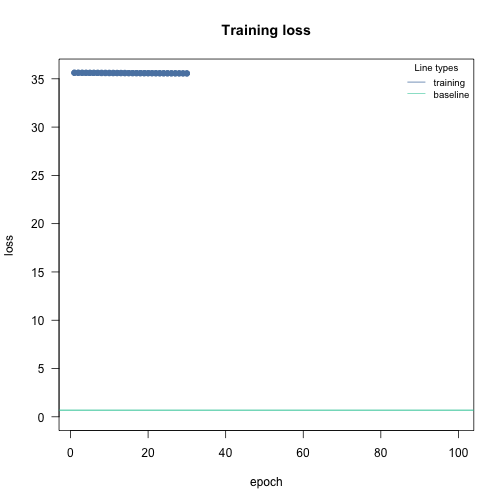
If it looks like that, go to the adjusting the learning rate section
-
Overfitting, difference between training and testing/holdout/new data error is too high, or validation loss first decreases but then increases again:
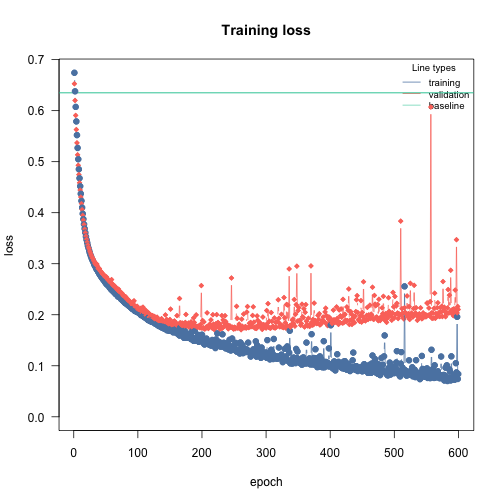
if it loos like that, go to the overfitting section
Convergence issues
Ensuring convergence can be tricky when training neural networks. Their training is sensitive to a combination of the learning rate (how much the weights are updated in each optimization step), the batch size (a random subset of the data is used in each optimization step), and the number of epochs (number of optimization steps).
Epochs
Give the neural network enough time to learn. The epochs should be high enough so that the training loss “stabilizes”:
m = dnn(Species~., data = iris, epochs = 10L, loss = "softmax", verbose=FALSE)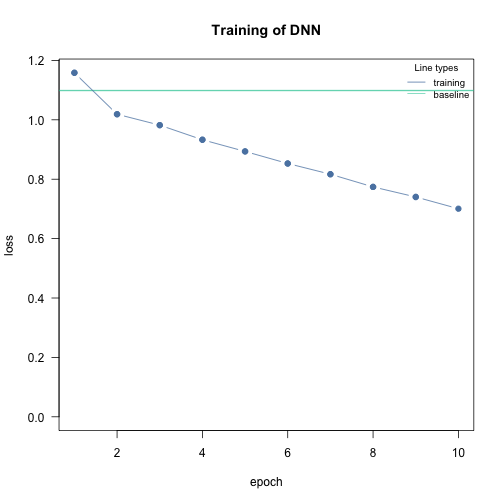
After 10 epochs the loss was still decreasing, we should train the model longer (increase epochs):
m = dnn(Species~., data = iris, epochs = 200L, loss = "softmax", verbose=FALSE)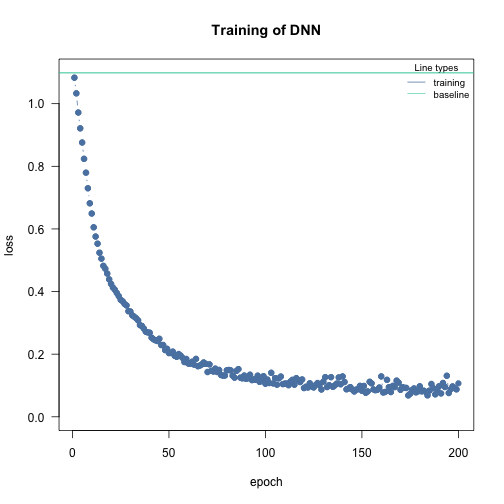
Here, it takes around 190-200 epochs until the loss doesn’t decrease anymore. The “speed” of the learning depends also on the learning rate. Higher rates means larger steps into direction of local minima in the loss function:
m = dnn(Species~., data = iris, epochs = 200L, loss = "softmax", lr = 0.05, verbose=FALSE)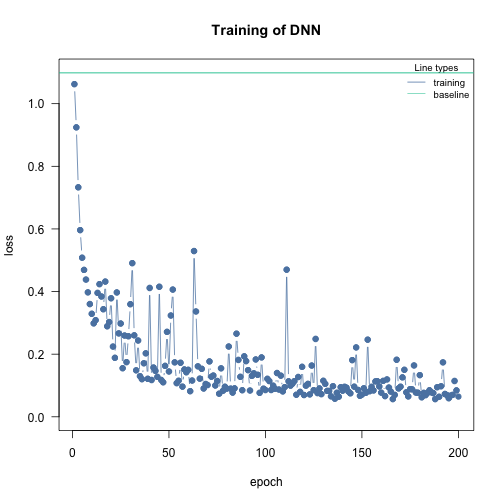
Now it only takes about 100 epochs, but we also see that the training loss becomes wobbly. Larger learning rates increase the probability that local minima are skipped and the optimizer has problems to hit a minima.
Note: But if the learning rate is high, or too high, the loss will get “jumpy”, the risk of the optimizer jumping over local minima increases (see next section).
Learning rate
Typically, the learning rate should be decreased with the size of the neural networks (depth of the network and width of the hidden layers). We provide a baseline loss (intercept only model) that can give hints about an appropriate learning rate.
nn.fit_good<- dnn(Species~., data = datasets::iris, lr = 0.09, epochs = 20L, loss = "softmax", verbose = FALSE, plot = FALSE)
nn.fit_high<- dnn(Species~., data = datasets::iris, lr = 2.09, epochs = 20L, loss = "softmax", verbose = FALSE, plot = FALSE)
nn.fit_low<- dnn(Species~., data = datasets::iris, lr = 0.00000001, epochs = 20L, loss = "softmax", verbose = FALSE, plot = FALSE)
par(mfrow = c(1, 3), mar = c(4, 3, 2, 2))
cito:::visualize.training(nn.fit_good$losses,main="Training loss", epoch = 20, new = TRUE, baseline = nn.fit_good$base_loss)
cito:::visualize.training(nn.fit_high$losses,main="Training loss", epoch = 20, new = TRUE, baseline = nn.fit_good$base_loss)
cito:::visualize.training(nn.fit_low$losses,main="Training loss", epoch = 20, new = TRUE, baseline = nn.fit_good$base_loss)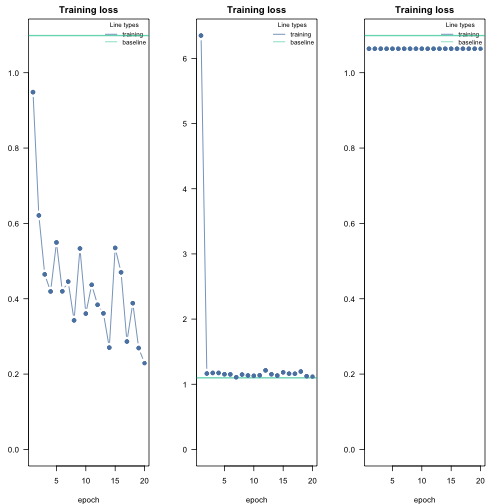
If the training loss of the model doesn’t fall below the baseline loss, the learning rate is either too high or too low. If this happens, try higher and lower learning rates.
A common strategy is to try (manually) a few different learning rates to see if the learning rate is on the right scale.
Solution: learning rate scheduler
A common strategy to deal with the learning rate problem is to start with a high learning rate, and if the loss does not decrease, the learning rate is reduced according to a specific plan.
I favor the “reduce learning rate on plateau” scheduler. If a loss plateau isn’t resolved for a certain number of epochs (patience), the learning rate will be reduced ():
nn.fit_high<- dnn(Species~., data = datasets::iris,
lr = 0.2,
epochs = 60L,
loss = "softmax",
lr_scheduler = config_lr_scheduler("reduce_on_plateau", patience = 5, factor = 0.5),
verbose = TRUE,
plot = TRUE)
#> Loss at epoch 1: 0.868813, lr: 0.20000
#> Loss at epoch 2: 0.607227, lr: 0.20000
#> Loss at epoch 3: 1.129801, lr: 0.20000
#> Loss at epoch 4: 0.498109, lr: 0.20000
#> Loss at epoch 5: 0.427480, lr: 0.20000
#> Loss at epoch 6: 0.505962, lr: 0.20000
#> Loss at epoch 7: 0.423542, lr: 0.20000
#> Loss at epoch 8: 0.398008, lr: 0.20000
#> Loss at epoch 9: 0.415886, lr: 0.20000
#> Loss at epoch 10: 0.310365, lr: 0.20000
#> Loss at epoch 11: 0.364727, lr: 0.20000
#> Loss at epoch 12: 0.405762, lr: 0.20000
#> Loss at epoch 13: 0.371685, lr: 0.20000
#> Loss at epoch 14: 0.606758, lr: 0.20000
#> Loss at epoch 15: 0.494564, lr: 0.20000
#> Loss at epoch 16: 0.386717, lr: 0.10000
#> Loss at epoch 17: 0.247253, lr: 0.10000
#> Loss at epoch 18: 0.196016, lr: 0.10000
#> Loss at epoch 19: 0.216442, lr: 0.10000
#> Loss at epoch 20: 0.229231, lr: 0.10000
#> Loss at epoch 21: 0.147426, lr: 0.10000
#> Loss at epoch 22: 0.168880, lr: 0.10000
#> Loss at epoch 23: 0.290900, lr: 0.10000
#> Loss at epoch 24: 0.279733, lr: 0.10000
#> Loss at epoch 25: 0.181382, lr: 0.10000
#> Loss at epoch 26: 0.274826, lr: 0.10000
#> Loss at epoch 27: 0.122269, lr: 0.10000
#> Loss at epoch 28: 0.278979, lr: 0.10000
#> Loss at epoch 29: 0.145546, lr: 0.10000
#> Loss at epoch 30: 0.232280, lr: 0.10000
#> Loss at epoch 31: 0.360600, lr: 0.10000
#> Loss at epoch 32: 0.133818, lr: 0.10000
#> Loss at epoch 33: 0.133925, lr: 0.05000
#> Loss at epoch 34: 0.117416, lr: 0.05000
#> Loss at epoch 35: 0.097019, lr: 0.05000
#> Loss at epoch 36: 0.095766, lr: 0.05000
#> Loss at epoch 37: 0.085271, lr: 0.05000
#> Loss at epoch 38: 0.081865, lr: 0.05000
#> Loss at epoch 39: 0.087199, lr: 0.05000
#> Loss at epoch 40: 0.086238, lr: 0.05000
#> Loss at epoch 41: 0.115600, lr: 0.05000
#> Loss at epoch 42: 0.101273, lr: 0.05000
#> Loss at epoch 43: 0.081162, lr: 0.05000
#> Loss at epoch 44: 0.093478, lr: 0.05000
#> Loss at epoch 45: 0.078520, lr: 0.05000
#> Loss at epoch 46: 0.112726, lr: 0.05000
#> Loss at epoch 47: 0.112692, lr: 0.05000
#> Loss at epoch 48: 0.093684, lr: 0.05000
#> Loss at epoch 49: 0.100669, lr: 0.05000
#> Loss at epoch 50: 0.081393, lr: 0.05000
#> Loss at epoch 51: 0.110707, lr: 0.02500
#> Loss at epoch 52: 0.079502, lr: 0.02500
#> Loss at epoch 53: 0.074759, lr: 0.02500
#> Loss at epoch 54: 0.071895, lr: 0.02500
#> Loss at epoch 55: 0.071452, lr: 0.02500
#> Loss at epoch 56: 0.072424, lr: 0.02500
#> Loss at epoch 57: 0.073547, lr: 0.02500
#> Loss at epoch 58: 0.073571, lr: 0.02500
#> Loss at epoch 59: 0.075333, lr: 0.02500
#> Loss at epoch 60: 0.071900, lr: 0.02500At the end of the training, the learning rate is 0.025
Note: The learning rate scheduler is a powerful approach to improve the likeliness of convergence, BUT it cannot help with much too high learning rates!
nn.fit_high<- dnn(Species~., data = datasets::iris,
lr = 2,
epochs = 60L,
loss = "softmax",
lr_scheduler = config_lr_scheduler("reduce_on_plateau", patience = 5, factor = 0.5),
verbose = TRUE,
plot = TRUE)
#> Loss at epoch 1: 782.251417, lr: 2.00000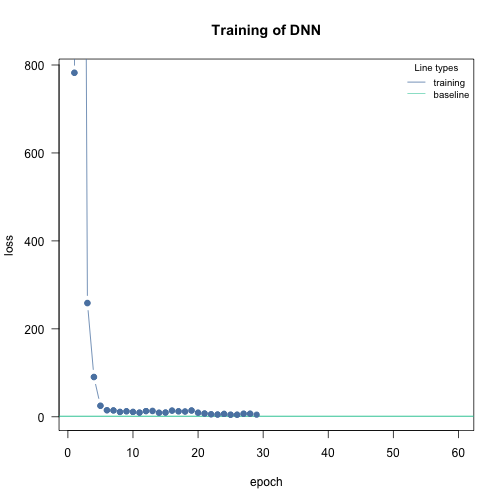
#> Loss at epoch 2: 3298.952477, lr: 2.00000
#> Loss at epoch 3: 258.680795, lr: 2.00000
#> Loss at epoch 4: 90.482500, lr: 2.00000
#> Loss at epoch 5: 25.033280, lr: 2.00000
#> Loss at epoch 6: 14.902886, lr: 2.00000
#> Loss at epoch 7: 14.502181, lr: 2.00000
#> Loss at epoch 8: 11.076120, lr: 2.00000
#> Loss at epoch 9: 12.562866, lr: 2.00000
#> Loss at epoch 10: 11.093193, lr: 2.00000
#> Loss at epoch 11: 9.510224, lr: 2.00000
#> Loss at epoch 12: 12.989465, lr: 2.00000
#> Loss at epoch 13: 13.282229, lr: 2.00000
#> Loss at epoch 14: 9.262714, lr: 2.00000
#> Loss at epoch 15: 9.705650, lr: 2.00000
#> Loss at epoch 16: 14.090702, lr: 2.00000
#> Loss at epoch 17: 12.523569, lr: 2.00000
#> Loss at epoch 18: 12.015066, lr: 2.00000
#> Loss at epoch 19: 14.319363, lr: 2.00000
#> Loss at epoch 20: 9.328203, lr: 1.00000
#> Loss at epoch 21: 7.450138, lr: 1.00000
#> Loss at epoch 22: 5.726156, lr: 1.00000
#> Loss at epoch 23: 5.152872, lr: 1.00000
#> Loss at epoch 24: 6.538125, lr: 1.00000
#> Loss at epoch 25: 4.690747, lr: 1.00000
#> Loss at epoch 26: 4.736277, lr: 1.00000
#> Loss at epoch 27: 6.920749, lr: 1.00000
#> Loss at epoch 28: 6.986071, lr: 1.00000
#> Loss at epoch 29: 4.831617, lr: 1.00000
#> Cancel training because loss is still above baseline, please hyperparameters. See vignette('B-Training_neural_networks') for help.Although the learning rate ended up being 0.01562, the loss never outperformed the baseline loss. The optimizer jumped right at the beginning into a completely unrealistic solution space for the parameters of the NN, from which we could not recover.
Overfitting
Overfitting means that the model fits the training data well, but generalizes poorly to new observations. We can use the validation argument to detect overfitting. If the validation loss starts to increase again at a certain point, it often means that the models are starting to overfit your training data:
library(EcoData) # can be install from github using devtools::install_github(repo = "TheoreticalEcology/EcoData", dependencies = FALSE, build_vignettes = FALSE)
df = elephant$occurenceData
m = dnn(Presence~., data = df, lr = 0.03, epochs = 600L, loss = "binomial", validation = 0.2, hidden = c(350L, 350L, 350L), activation = "relu", batchsize = 150L, verbose = FALSE, plot = TRUE)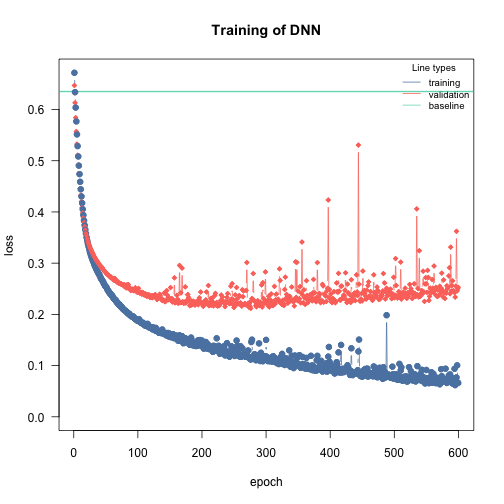
Solutions:
Re-train with epochs = point where model started to overfit
Early stopping, stop training when model starts to overfit, can be specified using the
early_stopping=…argumentUse regularization (dropout or elastic-net, see next section)
Early stopping and regularization
Early stopping = stop training when validation loss cannot be improved for x epochs (if there is no validation split, the training loss is used).
lambda = 0.001 is the regularization strength and alpha = 0.2 means that 20% L1 and 80% L2 weighting.
m = dnn(Presence~., data = df, lr = 0.03, epochs = 600L, loss = "binomial", validation = 0.2, hidden = c(350L, 350L, 350L), activation = "relu", batchsize = 150L, verbose = FALSE, plot = TRUE, early_stopping = 10, lambda = 0.001, alpha = 0.2)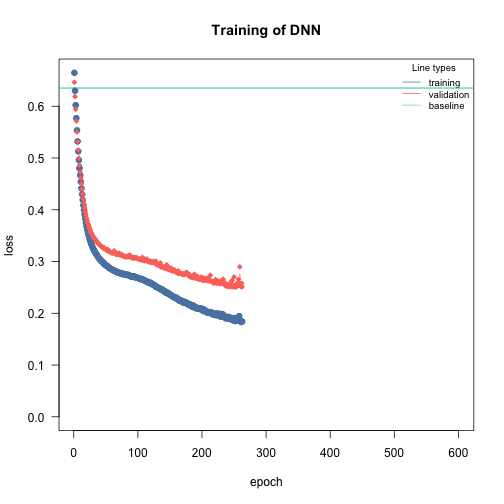
The training is aborted!