The 'cito' package provides a user-friendly interface for training and interpreting deep neural networks (DNN). 'cito' simplifies the fitting of DNNs by supporting the familiar formula syntax, hyperparameter tuning under cross-validation, and helps to detect and handle convergence problems. DNNs can be trained on CPU, GPU and MacOS GPUs. In addition, 'cito' has many downstream functionalities such as various explainable AI (xAI) metrics (e.g. variable importance, partial dependence plots, accumulated local effect plots, and effect estimates) to interpret trained DNNs. 'cito' optionally provides confidence intervals (and p-values) for all xAI metrics and predictions. At the same time, 'cito' is computationally efficient because it is based on the deep learning framework 'torch'. The 'torch' package is native to R, so no Python installation or other API is required for this package.
Details
Cito is built around its main function dnn, which creates and trains a deep neural network. Various tools for analyzing the trained neural network are available.
Installation
in order to install cito please follow these steps:
install.packages("cito")
install_torch(reinstall = TRUE)
cito functions and typical workflow
dnn: train deep neural networkanalyze_training: check for convergence by comparing training loss with baseline losscontinue_training: continues training of an existing cito dnn model for additional epochssummary.citodnn: extract xAI metrics/effects to understand how predictions are madePDP: plot the partial dependency plot for a specific featureALE: plot the accumulated local effect plot for a specific feature
Check out the vignettes for more details on training NN and how a typical workflow with 'cito' could look like.
Author
Maintainer: Maximilian Pichler maximilian.pichler@biologie.uni-regensburg.de (ORCID)
Authors:
Christian Amesöder Christian.Amesoeder@informatik.uni-regensburg.de
Other contributors:
Florian Hartig florian.hartig@biologie.uni-regensburg.de (ORCID) [contributor]
Armin Schenk armin.schenk99@gmail.com [contributor]
Examples
# \donttest{
if(torch::torch_is_installed()){
library(cito)
# Example workflow in cito
## Build and train Network
### softmax is used for multi-class responses (e.g., Species)
nn.fit<- dnn(Species~., data = datasets::iris, loss = "softmax")
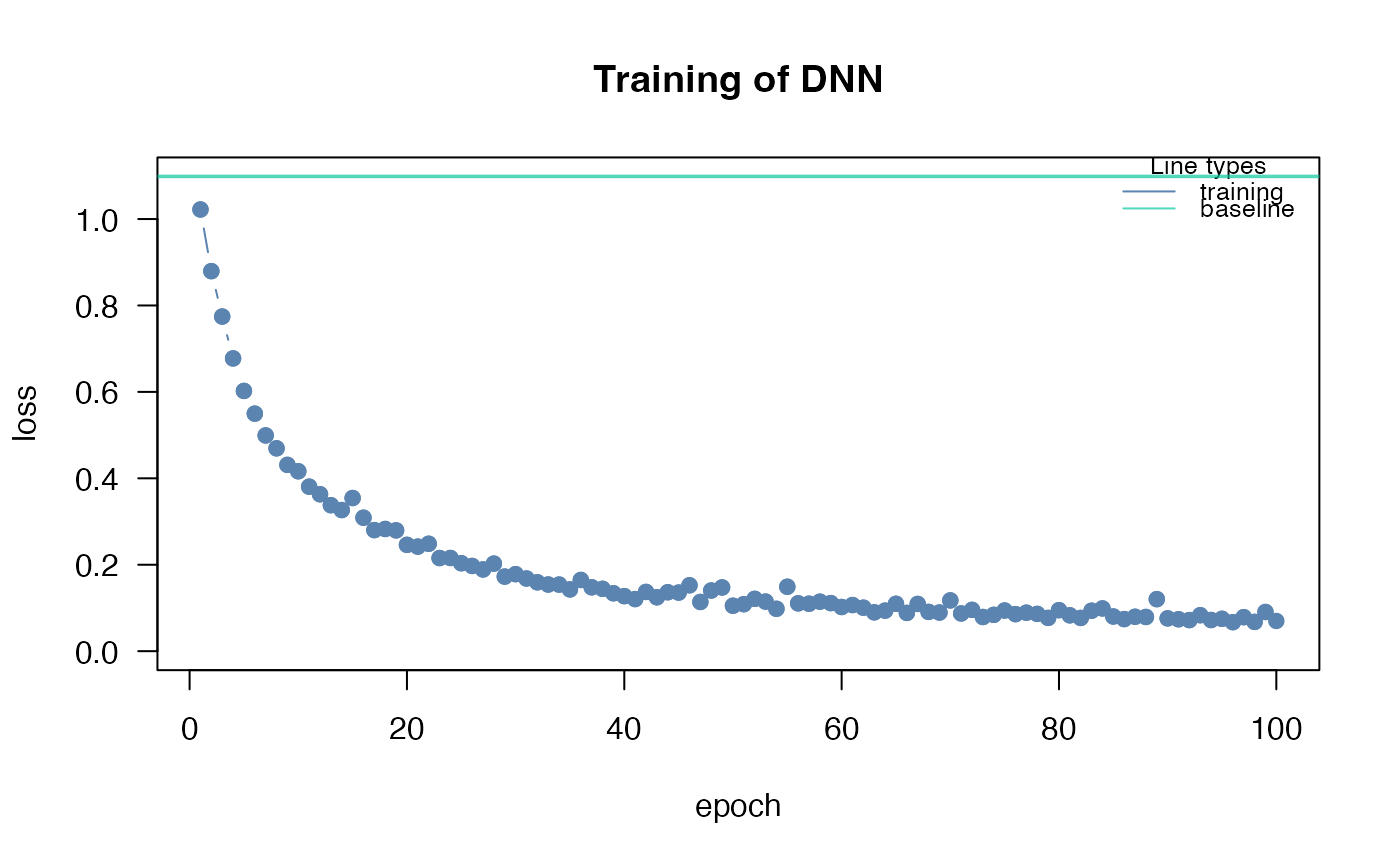
## The training loss is below the baseline loss but at the end of the
## training the loss was still decreasing, so continue training for another 50
## epochs
nn.fit <- continue_training(nn.fit, epochs = 50L)
# Sturcture of Neural Network
print(nn.fit)
# Plot Neural Network
plot(nn.fit)
## 4 Input nodes (first layer) because of 4 features
## 3 Output nodes (last layer) because of 3 response species (one node for each
## level in the response variable).
## The layers between the input and output layer are called hidden layers (two
## of them)
## We now want to understand how the predictions are made, what are the
## important features? The summary function automatically calculates feature
## importance (the interpretation is similar to an anova) and calculates
## average conditional effects that are similar to linear effects:
summary(nn.fit)
## To visualize the effect (response-feature effect), we can use the ALE and
## PDP functions
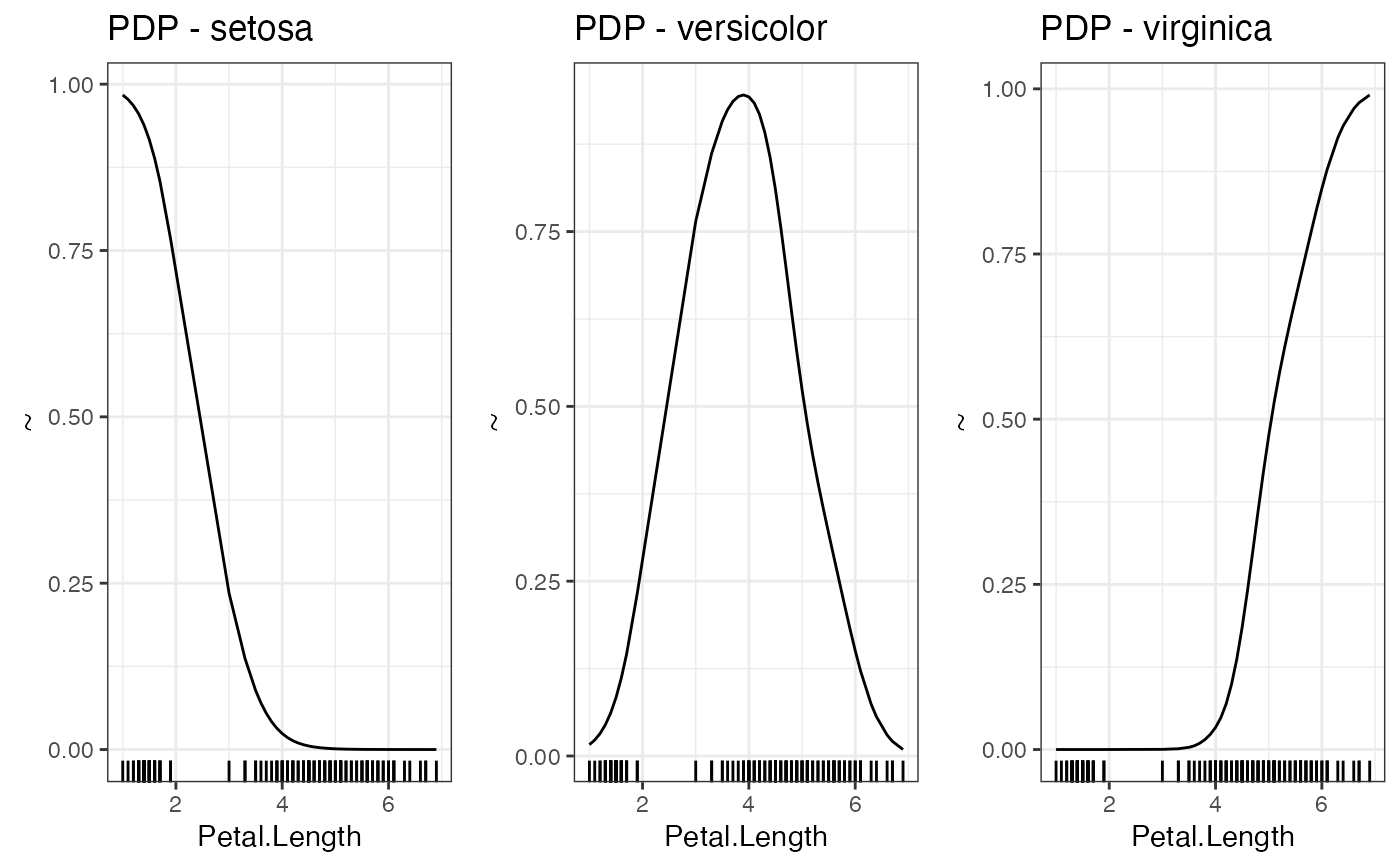
# Partial dependencies
PDP(nn.fit, variable = "Petal.Length")
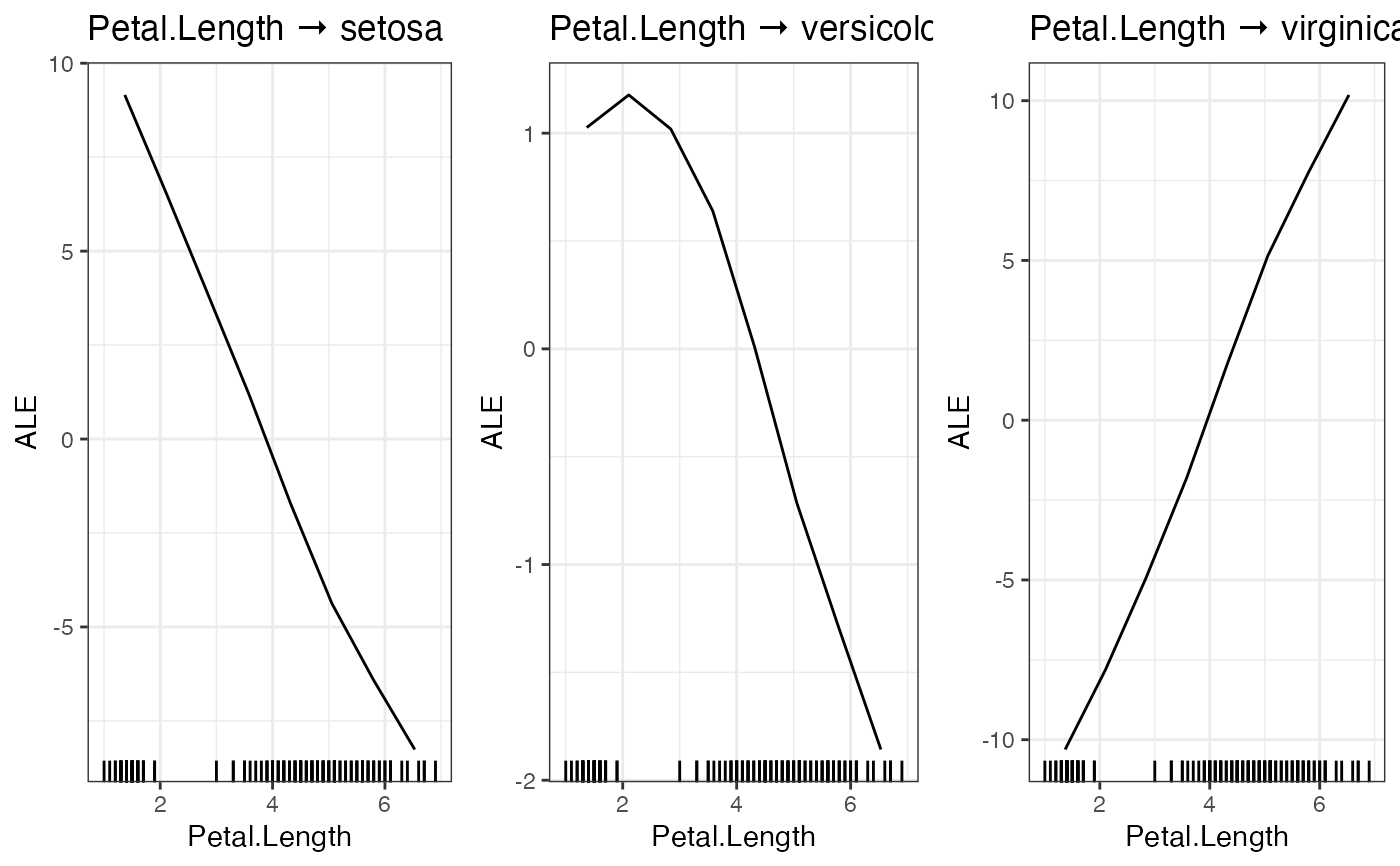
# Accumulated local effect plots
ALE(nn.fit, variable = "Petal.Length")
# Per se, it is difficult to get confidence intervals for our xAI metrics (or
# for the predictions). But we can use bootstrapping to obtain uncertainties
# for all cito outputs:
## Re-fit the neural network with bootstrapping
nn.fit<- dnn(Species~.,
data = datasets::iris,
loss = "softmax",
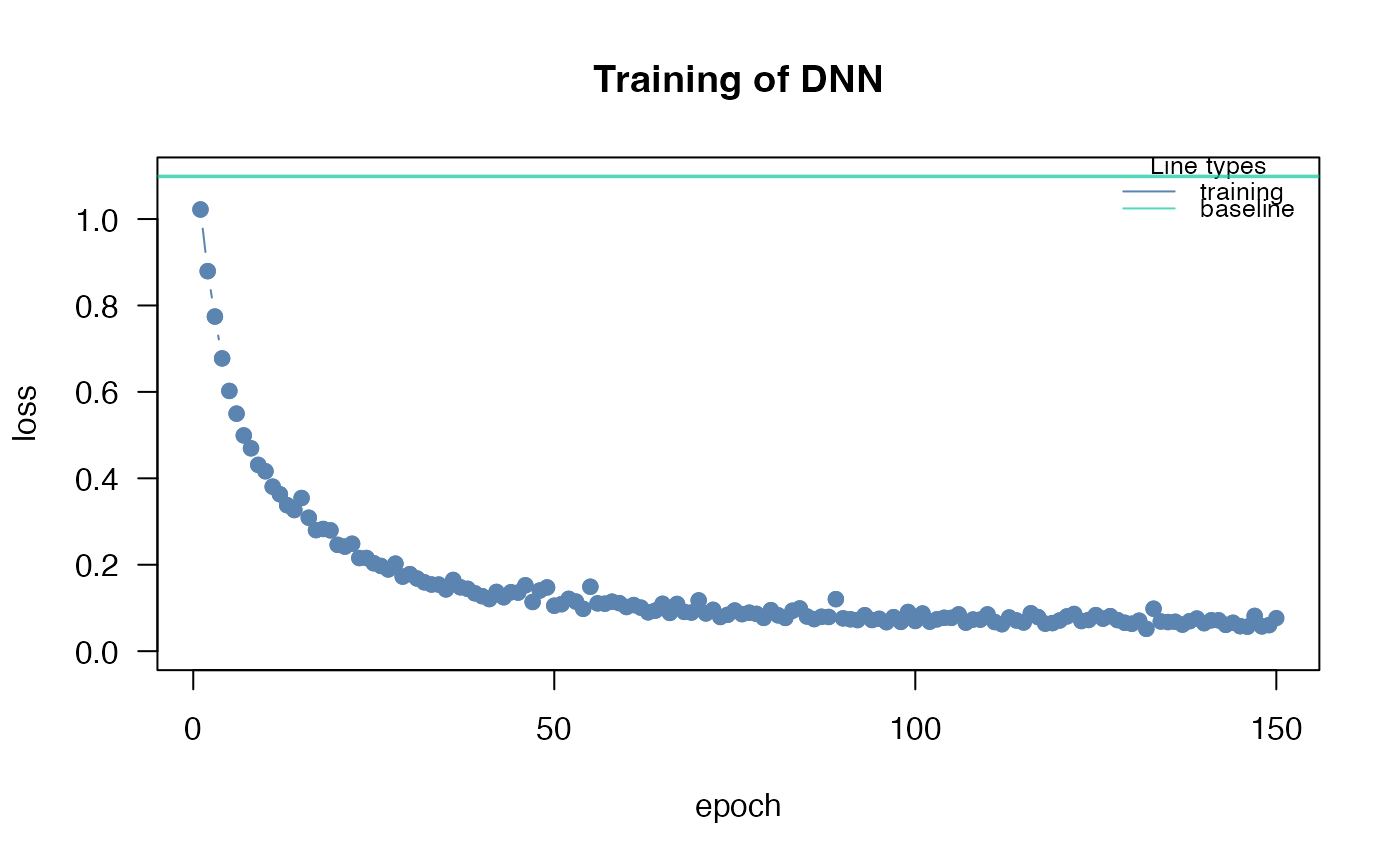
epochs = 150L,
verbose = FALSE,
bootstrap = 20L)
## convergence can be tested via the analyze_training function
analyze_training(nn.fit)
## Summary for xAI metrics (can take some time):
summary(nn.fit)
## Now with standard errors and p-values
## Note: Take the p-values with a grain of salt! We do not know yet if they are
## correct (e.g. if you use regularization, they are likely conservative == too
## large)
## Predictions with bootstrapping:
dim(predict(nn.fit))
## predictions are by default averaged (over the bootstrap samples)
## Multinomial and conditional logit regression
m = dnn(Species~., data = iris, loss = "clogit", lr = 0.01)
m = dnn(Species~., data = iris, loss = "multinomial", lr = 0.01)
Y = t(stats::rmultinom(100, 10, prob = c(0.2, 0.2, 0.5)))
m = dnn(cbind(X1, X2, X3)~., data = data.frame(Y, A = as.factor(runif(100))), loss = "multinomial", lr = 0.01)
## conditional logit for size > 1 is not supported yet
# Hyperparameter tuning (experimental feature)
hidden_values = matrix(c(5, 2,
4, 2,
10,2,
15,2), 4, 2, byrow = TRUE)
## Potential architectures we want to test, first column == number of nodes
print(hidden_values)
nn.fit = dnn(Species~.,
data = iris,
epochs = 30L,
loss = "softmax",
hidden = tune(values = hidden_values),
lr = tune(0.00001, 0.1) # tune lr between range 0.00001 and 0.1
)
## Tuning results:
print(nn.fit$tuning)
# test = Inf means that tuning was cancelled after only one fit (within the CV)
# Advanced: Custom loss functions and additional parameters
## Normal Likelihood with sd parameter:
custom_loss = function(pred, true) {
logLik = torch::distr_normal(pred,
scale = torch::nnf_relu(scale)+
0.001)$log_prob(true)
return(-logLik$mean())
}
nn.fit<- dnn(Sepal.Length~.,
data = datasets::iris,
loss = custom_loss,
verbose = FALSE,
custom_parameters = list(scale = 1.0)
)
nn.fit$parameter$scale
## Multivariate normal likelihood with parametrized covariance matrix
## Sigma = L*L^t + D
## Helper function to build covariance matrix
create_cov = function(LU, Diag) {
return(torch::torch_matmul(LU, LU$t()) + torch::torch_diag(Diag$exp()+0.01))
}
custom_loss_MVN = function(true, pred) {
Sigma = create_cov(SigmaPar, SigmaDiag)
logLik = torch::distr_multivariate_normal(pred,
covariance_matrix = Sigma)$
log_prob(true)
return(-logLik$mean())
}
nn.fit<- dnn(cbind(Sepal.Length, Sepal.Width, Petal.Length)~.,
data = datasets::iris,
lr = 0.01,
verbose = FALSE,
loss = custom_loss_MVN,
custom_parameters =
list(SigmaDiag = rep(0, 3),
SigmaPar = matrix(rnorm(6, sd = 0.001), 3, 2))
)
as.matrix(create_cov(nn.fit$loss$parameter$SigmaPar,
nn.fit$loss$parameter$SigmaDiag))
}
#> Loss at epoch 1: 1.028129, lr: 0.01000
 #> Loss at epoch 2: 0.901958, lr: 0.01000
#> Loss at epoch 3: 0.796776, lr: 0.01000
#> Loss at epoch 4: 0.729468, lr: 0.01000
#> Loss at epoch 5: 0.644836, lr: 0.01000
#> Loss at epoch 6: 0.636941, lr: 0.01000
#> Loss at epoch 7: 0.574591, lr: 0.01000
#> Loss at epoch 8: 0.535066, lr: 0.01000
#> Loss at epoch 9: 0.495465, lr: 0.01000
#> Loss at epoch 10: 0.491982, lr: 0.01000
#> Loss at epoch 11: 0.455357, lr: 0.01000
#> Loss at epoch 12: 0.440196, lr: 0.01000
#> Loss at epoch 13: 0.423234, lr: 0.01000
#> Loss at epoch 14: 0.404440, lr: 0.01000
#> Loss at epoch 15: 0.389705, lr: 0.01000
#> Loss at epoch 16: 0.373012, lr: 0.01000
#> Loss at epoch 17: 0.364483, lr: 0.01000
#> Loss at epoch 18: 0.347243, lr: 0.01000
#> Loss at epoch 19: 0.325396, lr: 0.01000
#> Loss at epoch 20: 0.319343, lr: 0.01000
#> Loss at epoch 21: 0.302919, lr: 0.01000
#> Loss at epoch 22: 0.308175, lr: 0.01000
#> Loss at epoch 23: 0.285796, lr: 0.01000
#> Loss at epoch 24: 0.304754, lr: 0.01000
#> Loss at epoch 25: 0.285883, lr: 0.01000
#> Loss at epoch 26: 0.265439, lr: 0.01000
#> Loss at epoch 27: 0.251801, lr: 0.01000
#> Loss at epoch 28: 0.243715, lr: 0.01000
#> Loss at epoch 29: 0.237872, lr: 0.01000
#> Loss at epoch 30: 0.227322, lr: 0.01000
#> Loss at epoch 31: 0.217828, lr: 0.01000
#> Loss at epoch 32: 0.211607, lr: 0.01000
#> Loss at epoch 33: 0.207035, lr: 0.01000
#> Loss at epoch 34: 0.215674, lr: 0.01000
#> Loss at epoch 35: 0.194667, lr: 0.01000
#> Loss at epoch 36: 0.193276, lr: 0.01000
#> Loss at epoch 37: 0.191401, lr: 0.01000
#> Loss at epoch 38: 0.173749, lr: 0.01000
#> Loss at epoch 39: 0.173219, lr: 0.01000
#> Loss at epoch 40: 0.189330, lr: 0.01000
#> Loss at epoch 41: 0.178352, lr: 0.01000
#> Loss at epoch 42: 0.165828, lr: 0.01000
#> Loss at epoch 43: 0.160566, lr: 0.01000
#> Loss at epoch 44: 0.175424, lr: 0.01000
#> Loss at epoch 45: 0.160873, lr: 0.01000
#> Loss at epoch 46: 0.162290, lr: 0.01000
#> Loss at epoch 47: 0.170782, lr: 0.01000
#> Loss at epoch 48: 0.142525, lr: 0.01000
#> Loss at epoch 49: 0.136984, lr: 0.01000
#> Loss at epoch 50: 0.134339, lr: 0.01000
#> Loss at epoch 51: 0.149776, lr: 0.01000
#> Loss at epoch 52: 0.139126, lr: 0.01000
#> Loss at epoch 53: 0.145396, lr: 0.01000
#> Loss at epoch 54: 0.132434, lr: 0.01000
#> Loss at epoch 55: 0.139382, lr: 0.01000
#> Loss at epoch 56: 0.121038, lr: 0.01000
#> Loss at epoch 57: 0.111437, lr: 0.01000
#> Loss at epoch 58: 0.120576, lr: 0.01000
#> Loss at epoch 59: 0.126434, lr: 0.01000
#> Loss at epoch 60: 0.122956, lr: 0.01000
#> Loss at epoch 61: 0.135895, lr: 0.01000
#> Loss at epoch 62: 0.118843, lr: 0.01000
#> Loss at epoch 63: 0.119675, lr: 0.01000
#> Loss at epoch 64: 0.155256, lr: 0.01000
#> Loss at epoch 65: 0.137365, lr: 0.01000
#> Loss at epoch 66: 0.112379, lr: 0.01000
#> Loss at epoch 67: 0.102348, lr: 0.01000
#> Loss at epoch 68: 0.106337, lr: 0.01000
#> Loss at epoch 69: 0.106938, lr: 0.01000
#> Loss at epoch 70: 0.104467, lr: 0.01000
#> Loss at epoch 71: 0.097326, lr: 0.01000
#> Loss at epoch 72: 0.117703, lr: 0.01000
#> Loss at epoch 73: 0.100832, lr: 0.01000
#> Loss at epoch 74: 0.113942, lr: 0.01000
#> Loss at epoch 75: 0.098676, lr: 0.01000
#> Loss at epoch 76: 0.104589, lr: 0.01000
#> Loss at epoch 77: 0.100378, lr: 0.01000
#> Loss at epoch 78: 0.093891, lr: 0.01000
#> Loss at epoch 79: 0.093112, lr: 0.01000
#> Loss at epoch 80: 0.094668, lr: 0.01000
#> Loss at epoch 81: 0.118778, lr: 0.01000
#> Loss at epoch 82: 0.088652, lr: 0.01000
#> Loss at epoch 83: 0.092798, lr: 0.01000
#> Loss at epoch 84: 0.089796, lr: 0.01000
#> Loss at epoch 85: 0.102770, lr: 0.01000
#> Loss at epoch 86: 0.095056, lr: 0.01000
#> Loss at epoch 87: 0.115043, lr: 0.01000
#> Loss at epoch 88: 0.095890, lr: 0.01000
#> Loss at epoch 89: 0.094287, lr: 0.01000
#> Loss at epoch 90: 0.079088, lr: 0.01000
#> Loss at epoch 91: 0.119451, lr: 0.01000
#> Loss at epoch 92: 0.088465, lr: 0.01000
#> Loss at epoch 93: 0.098638, lr: 0.01000
#> Loss at epoch 94: 0.092730, lr: 0.01000
#> Loss at epoch 95: 0.085831, lr: 0.01000
#> Loss at epoch 96: 0.088967, lr: 0.01000
#> Loss at epoch 97: 0.094985, lr: 0.01000
#> Loss at epoch 98: 0.108592, lr: 0.01000
#> Loss at epoch 99: 0.077884, lr: 0.01000
#> Loss at epoch 100: 0.088470, lr: 0.01000
#> Loss at epoch 101: 0.095510, lr: 0.01000
#> Loss at epoch 2: 0.901958, lr: 0.01000
#> Loss at epoch 3: 0.796776, lr: 0.01000
#> Loss at epoch 4: 0.729468, lr: 0.01000
#> Loss at epoch 5: 0.644836, lr: 0.01000
#> Loss at epoch 6: 0.636941, lr: 0.01000
#> Loss at epoch 7: 0.574591, lr: 0.01000
#> Loss at epoch 8: 0.535066, lr: 0.01000
#> Loss at epoch 9: 0.495465, lr: 0.01000
#> Loss at epoch 10: 0.491982, lr: 0.01000
#> Loss at epoch 11: 0.455357, lr: 0.01000
#> Loss at epoch 12: 0.440196, lr: 0.01000
#> Loss at epoch 13: 0.423234, lr: 0.01000
#> Loss at epoch 14: 0.404440, lr: 0.01000
#> Loss at epoch 15: 0.389705, lr: 0.01000
#> Loss at epoch 16: 0.373012, lr: 0.01000
#> Loss at epoch 17: 0.364483, lr: 0.01000
#> Loss at epoch 18: 0.347243, lr: 0.01000
#> Loss at epoch 19: 0.325396, lr: 0.01000
#> Loss at epoch 20: 0.319343, lr: 0.01000
#> Loss at epoch 21: 0.302919, lr: 0.01000
#> Loss at epoch 22: 0.308175, lr: 0.01000
#> Loss at epoch 23: 0.285796, lr: 0.01000
#> Loss at epoch 24: 0.304754, lr: 0.01000
#> Loss at epoch 25: 0.285883, lr: 0.01000
#> Loss at epoch 26: 0.265439, lr: 0.01000
#> Loss at epoch 27: 0.251801, lr: 0.01000
#> Loss at epoch 28: 0.243715, lr: 0.01000
#> Loss at epoch 29: 0.237872, lr: 0.01000
#> Loss at epoch 30: 0.227322, lr: 0.01000
#> Loss at epoch 31: 0.217828, lr: 0.01000
#> Loss at epoch 32: 0.211607, lr: 0.01000
#> Loss at epoch 33: 0.207035, lr: 0.01000
#> Loss at epoch 34: 0.215674, lr: 0.01000
#> Loss at epoch 35: 0.194667, lr: 0.01000
#> Loss at epoch 36: 0.193276, lr: 0.01000
#> Loss at epoch 37: 0.191401, lr: 0.01000
#> Loss at epoch 38: 0.173749, lr: 0.01000
#> Loss at epoch 39: 0.173219, lr: 0.01000
#> Loss at epoch 40: 0.189330, lr: 0.01000
#> Loss at epoch 41: 0.178352, lr: 0.01000
#> Loss at epoch 42: 0.165828, lr: 0.01000
#> Loss at epoch 43: 0.160566, lr: 0.01000
#> Loss at epoch 44: 0.175424, lr: 0.01000
#> Loss at epoch 45: 0.160873, lr: 0.01000
#> Loss at epoch 46: 0.162290, lr: 0.01000
#> Loss at epoch 47: 0.170782, lr: 0.01000
#> Loss at epoch 48: 0.142525, lr: 0.01000
#> Loss at epoch 49: 0.136984, lr: 0.01000
#> Loss at epoch 50: 0.134339, lr: 0.01000
#> Loss at epoch 51: 0.149776, lr: 0.01000
#> Loss at epoch 52: 0.139126, lr: 0.01000
#> Loss at epoch 53: 0.145396, lr: 0.01000
#> Loss at epoch 54: 0.132434, lr: 0.01000
#> Loss at epoch 55: 0.139382, lr: 0.01000
#> Loss at epoch 56: 0.121038, lr: 0.01000
#> Loss at epoch 57: 0.111437, lr: 0.01000
#> Loss at epoch 58: 0.120576, lr: 0.01000
#> Loss at epoch 59: 0.126434, lr: 0.01000
#> Loss at epoch 60: 0.122956, lr: 0.01000
#> Loss at epoch 61: 0.135895, lr: 0.01000
#> Loss at epoch 62: 0.118843, lr: 0.01000
#> Loss at epoch 63: 0.119675, lr: 0.01000
#> Loss at epoch 64: 0.155256, lr: 0.01000
#> Loss at epoch 65: 0.137365, lr: 0.01000
#> Loss at epoch 66: 0.112379, lr: 0.01000
#> Loss at epoch 67: 0.102348, lr: 0.01000
#> Loss at epoch 68: 0.106337, lr: 0.01000
#> Loss at epoch 69: 0.106938, lr: 0.01000
#> Loss at epoch 70: 0.104467, lr: 0.01000
#> Loss at epoch 71: 0.097326, lr: 0.01000
#> Loss at epoch 72: 0.117703, lr: 0.01000
#> Loss at epoch 73: 0.100832, lr: 0.01000
#> Loss at epoch 74: 0.113942, lr: 0.01000
#> Loss at epoch 75: 0.098676, lr: 0.01000
#> Loss at epoch 76: 0.104589, lr: 0.01000
#> Loss at epoch 77: 0.100378, lr: 0.01000
#> Loss at epoch 78: 0.093891, lr: 0.01000
#> Loss at epoch 79: 0.093112, lr: 0.01000
#> Loss at epoch 80: 0.094668, lr: 0.01000
#> Loss at epoch 81: 0.118778, lr: 0.01000
#> Loss at epoch 82: 0.088652, lr: 0.01000
#> Loss at epoch 83: 0.092798, lr: 0.01000
#> Loss at epoch 84: 0.089796, lr: 0.01000
#> Loss at epoch 85: 0.102770, lr: 0.01000
#> Loss at epoch 86: 0.095056, lr: 0.01000
#> Loss at epoch 87: 0.115043, lr: 0.01000
#> Loss at epoch 88: 0.095890, lr: 0.01000
#> Loss at epoch 89: 0.094287, lr: 0.01000
#> Loss at epoch 90: 0.079088, lr: 0.01000
#> Loss at epoch 91: 0.119451, lr: 0.01000
#> Loss at epoch 92: 0.088465, lr: 0.01000
#> Loss at epoch 93: 0.098638, lr: 0.01000
#> Loss at epoch 94: 0.092730, lr: 0.01000
#> Loss at epoch 95: 0.085831, lr: 0.01000
#> Loss at epoch 96: 0.088967, lr: 0.01000
#> Loss at epoch 97: 0.094985, lr: 0.01000
#> Loss at epoch 98: 0.108592, lr: 0.01000
#> Loss at epoch 99: 0.077884, lr: 0.01000
#> Loss at epoch 100: 0.088470, lr: 0.01000
#> Loss at epoch 101: 0.095510, lr: 0.01000
 #> Loss at epoch 102: 0.089307, lr: 0.01000
#> Loss at epoch 103: 0.071911, lr: 0.01000
#> Loss at epoch 104: 0.095836, lr: 0.01000
#> Loss at epoch 105: 0.074341, lr: 0.01000
#> Loss at epoch 106: 0.083014, lr: 0.01000
#> Loss at epoch 107: 0.090436, lr: 0.01000
#> Loss at epoch 108: 0.081577, lr: 0.01000
#> Loss at epoch 109: 0.102380, lr: 0.01000
#> Loss at epoch 110: 0.082503, lr: 0.01000
#> Loss at epoch 111: 0.087474, lr: 0.01000
#> Loss at epoch 112: 0.077108, lr: 0.01000
#> Loss at epoch 113: 0.114079, lr: 0.01000
#> Loss at epoch 114: 0.100395, lr: 0.01000
#> Loss at epoch 115: 0.083112, lr: 0.01000
#> Loss at epoch 116: 0.094819, lr: 0.01000
#> Loss at epoch 117: 0.076733, lr: 0.01000
#> Loss at epoch 118: 0.091762, lr: 0.01000
#> Loss at epoch 119: 0.065681, lr: 0.01000
#> Loss at epoch 120: 0.085504, lr: 0.01000
#> Loss at epoch 121: 0.069642, lr: 0.01000
#> Loss at epoch 122: 0.070765, lr: 0.01000
#> Loss at epoch 123: 0.074615, lr: 0.01000
#> Loss at epoch 124: 0.084287, lr: 0.01000
#> Loss at epoch 125: 0.074067, lr: 0.01000
#> Loss at epoch 126: 0.097645, lr: 0.01000
#> Loss at epoch 127: 0.090851, lr: 0.01000
#> Loss at epoch 128: 0.068881, lr: 0.01000
#> Loss at epoch 129: 0.081341, lr: 0.01000
#> Loss at epoch 130: 0.066448, lr: 0.01000
#> Loss at epoch 131: 0.087900, lr: 0.01000
#> Loss at epoch 132: 0.082455, lr: 0.01000
#> Loss at epoch 133: 0.070454, lr: 0.01000
#> Loss at epoch 134: 0.106875, lr: 0.01000
#> Loss at epoch 135: 0.080947, lr: 0.01000
#> Loss at epoch 136: 0.072918, lr: 0.01000
#> Loss at epoch 137: 0.075408, lr: 0.01000
#> Loss at epoch 138: 0.065989, lr: 0.01000
#> Loss at epoch 139: 0.073839, lr: 0.01000
#> Loss at epoch 140: 0.083702, lr: 0.01000
#> Loss at epoch 141: 0.067250, lr: 0.01000
#> Loss at epoch 142: 0.073940, lr: 0.01000
#> Loss at epoch 143: 0.079373, lr: 0.01000
#> Loss at epoch 144: 0.078913, lr: 0.01000
#> Loss at epoch 145: 0.066251, lr: 0.01000
#> Loss at epoch 146: 0.095477, lr: 0.01000
#> Loss at epoch 147: 0.079328, lr: 0.01000
#> Loss at epoch 148: 0.101016, lr: 0.01000
#> Loss at epoch 149: 0.083090, lr: 0.01000
#> Loss at epoch 150: 0.077563, lr: 0.01000
#> dnn(formula = Species ~ Sepal.Length + Sepal.Width + Petal.Length +
#> Petal.Width, data = datasets::iris, loss = "softmax")
#> An `nn_module` containing 2,953 parameters.
#>
#> ── Modules ─────────────────────────────────────────────────────────────────────
#> • 0: <nn_linear> #250 parameters
#> • 1: <nn_selu> #0 parameters
#> • 2: <nn_linear> #2,550 parameters
#> • 3: <nn_selu> #0 parameters
#> • 4: <nn_linear> #153 parameters
#> Loss at epoch 102: 0.089307, lr: 0.01000
#> Loss at epoch 103: 0.071911, lr: 0.01000
#> Loss at epoch 104: 0.095836, lr: 0.01000
#> Loss at epoch 105: 0.074341, lr: 0.01000
#> Loss at epoch 106: 0.083014, lr: 0.01000
#> Loss at epoch 107: 0.090436, lr: 0.01000
#> Loss at epoch 108: 0.081577, lr: 0.01000
#> Loss at epoch 109: 0.102380, lr: 0.01000
#> Loss at epoch 110: 0.082503, lr: 0.01000
#> Loss at epoch 111: 0.087474, lr: 0.01000
#> Loss at epoch 112: 0.077108, lr: 0.01000
#> Loss at epoch 113: 0.114079, lr: 0.01000
#> Loss at epoch 114: 0.100395, lr: 0.01000
#> Loss at epoch 115: 0.083112, lr: 0.01000
#> Loss at epoch 116: 0.094819, lr: 0.01000
#> Loss at epoch 117: 0.076733, lr: 0.01000
#> Loss at epoch 118: 0.091762, lr: 0.01000
#> Loss at epoch 119: 0.065681, lr: 0.01000
#> Loss at epoch 120: 0.085504, lr: 0.01000
#> Loss at epoch 121: 0.069642, lr: 0.01000
#> Loss at epoch 122: 0.070765, lr: 0.01000
#> Loss at epoch 123: 0.074615, lr: 0.01000
#> Loss at epoch 124: 0.084287, lr: 0.01000
#> Loss at epoch 125: 0.074067, lr: 0.01000
#> Loss at epoch 126: 0.097645, lr: 0.01000
#> Loss at epoch 127: 0.090851, lr: 0.01000
#> Loss at epoch 128: 0.068881, lr: 0.01000
#> Loss at epoch 129: 0.081341, lr: 0.01000
#> Loss at epoch 130: 0.066448, lr: 0.01000
#> Loss at epoch 131: 0.087900, lr: 0.01000
#> Loss at epoch 132: 0.082455, lr: 0.01000
#> Loss at epoch 133: 0.070454, lr: 0.01000
#> Loss at epoch 134: 0.106875, lr: 0.01000
#> Loss at epoch 135: 0.080947, lr: 0.01000
#> Loss at epoch 136: 0.072918, lr: 0.01000
#> Loss at epoch 137: 0.075408, lr: 0.01000
#> Loss at epoch 138: 0.065989, lr: 0.01000
#> Loss at epoch 139: 0.073839, lr: 0.01000
#> Loss at epoch 140: 0.083702, lr: 0.01000
#> Loss at epoch 141: 0.067250, lr: 0.01000
#> Loss at epoch 142: 0.073940, lr: 0.01000
#> Loss at epoch 143: 0.079373, lr: 0.01000
#> Loss at epoch 144: 0.078913, lr: 0.01000
#> Loss at epoch 145: 0.066251, lr: 0.01000
#> Loss at epoch 146: 0.095477, lr: 0.01000
#> Loss at epoch 147: 0.079328, lr: 0.01000
#> Loss at epoch 148: 0.101016, lr: 0.01000
#> Loss at epoch 149: 0.083090, lr: 0.01000
#> Loss at epoch 150: 0.077563, lr: 0.01000
#> dnn(formula = Species ~ Sepal.Length + Sepal.Width + Petal.Length +
#> Petal.Width, data = datasets::iris, loss = "softmax")
#> An `nn_module` containing 2,953 parameters.
#>
#> ── Modules ─────────────────────────────────────────────────────────────────────
#> • 0: <nn_linear> #250 parameters
#> • 1: <nn_selu> #0 parameters
#> • 2: <nn_linear> #2,550 parameters
#> • 3: <nn_selu> #0 parameters
#> • 4: <nn_linear> #153 parameters

 #> Number of Neighborhoods reduced to 8
#> Number of Neighborhoods reduced to 8
#> Number of Neighborhoods reduced to 8
#> Number of Neighborhoods reduced to 8
#> Number of Neighborhoods reduced to 8
#> Number of Neighborhoods reduced to 8
 #> Loss at epoch 1: 0.621228, lr: 0.01000
#> Loss at epoch 1: 0.621228, lr: 0.01000
 #> Loss at epoch 2: 0.580236, lr: 0.01000
#> Loss at epoch 3: 0.549974, lr: 0.01000
#> Loss at epoch 4: 0.516203, lr: 0.01000
#> Loss at epoch 5: 0.492190, lr: 0.01000
#> Loss at epoch 6: 0.467423, lr: 0.01000
#> Loss at epoch 7: 0.445653, lr: 0.01000
#> Loss at epoch 8: 0.425039, lr: 0.01000
#> Loss at epoch 9: 0.405358, lr: 0.01000
#> Loss at epoch 10: 0.386309, lr: 0.01000
#> Loss at epoch 11: 0.372660, lr: 0.01000
#> Loss at epoch 12: 0.359912, lr: 0.01000
#> Loss at epoch 13: 0.347467, lr: 0.01000
#> Loss at epoch 14: 0.333965, lr: 0.01000
#> Loss at epoch 15: 0.324504, lr: 0.01000
#> Loss at epoch 16: 0.316904, lr: 0.01000
#> Loss at epoch 17: 0.304670, lr: 0.01000
#> Loss at epoch 18: 0.293441, lr: 0.01000
#> Loss at epoch 19: 0.287496, lr: 0.01000
#> Loss at epoch 20: 0.278483, lr: 0.01000
#> Loss at epoch 21: 0.273015, lr: 0.01000
#> Loss at epoch 22: 0.264038, lr: 0.01000
#> Loss at epoch 23: 0.259724, lr: 0.01000
#> Loss at epoch 24: 0.254735, lr: 0.01000
#> Loss at epoch 25: 0.243558, lr: 0.01000
#> Loss at epoch 26: 0.241815, lr: 0.01000
#> Loss at epoch 27: 0.232573, lr: 0.01000
#> Loss at epoch 28: 0.225291, lr: 0.01000
#> Loss at epoch 29: 0.219698, lr: 0.01000
#> Loss at epoch 30: 0.216967, lr: 0.01000
#> Loss at epoch 31: 0.213643, lr: 0.01000
#> Loss at epoch 32: 0.209031, lr: 0.01000
#> Loss at epoch 33: 0.201099, lr: 0.01000
#> Loss at epoch 34: 0.196401, lr: 0.01000
#> Loss at epoch 35: 0.190332, lr: 0.01000
#> Loss at epoch 36: 0.188689, lr: 0.01000
#> Loss at epoch 37: 0.180711, lr: 0.01000
#> Loss at epoch 38: 0.181188, lr: 0.01000
#> Loss at epoch 39: 0.169237, lr: 0.01000
#> Loss at epoch 40: 0.170794, lr: 0.01000
#> Loss at epoch 41: 0.164362, lr: 0.01000
#> Loss at epoch 42: 0.161676, lr: 0.01000
#> Loss at epoch 43: 0.158048, lr: 0.01000
#> Loss at epoch 44: 0.151875, lr: 0.01000
#> Loss at epoch 45: 0.151100, lr: 0.01000
#> Loss at epoch 46: 0.147166, lr: 0.01000
#> Loss at epoch 47: 0.142907, lr: 0.01000
#> Loss at epoch 48: 0.141146, lr: 0.01000
#> Loss at epoch 49: 0.136725, lr: 0.01000
#> Loss at epoch 50: 0.132671, lr: 0.01000
#> Loss at epoch 51: 0.130276, lr: 0.01000
#> Loss at epoch 52: 0.130272, lr: 0.01000
#> Loss at epoch 53: 0.128855, lr: 0.01000
#> Loss at epoch 54: 0.129522, lr: 0.01000
#> Loss at epoch 55: 0.121622, lr: 0.01000
#> Loss at epoch 56: 0.119577, lr: 0.01000
#> Loss at epoch 57: 0.115492, lr: 0.01000
#> Loss at epoch 58: 0.116751, lr: 0.01000
#> Loss at epoch 59: 0.118607, lr: 0.01000
#> Loss at epoch 60: 0.112974, lr: 0.01000
#> Loss at epoch 61: 0.105417, lr: 0.01000
#> Loss at epoch 62: 0.108555, lr: 0.01000
#> Loss at epoch 63: 0.108640, lr: 0.01000
#> Loss at epoch 64: 0.101279, lr: 0.01000
#> Loss at epoch 65: 0.103371, lr: 0.01000
#> Loss at epoch 66: 0.100340, lr: 0.01000
#> Loss at epoch 67: 0.098973, lr: 0.01000
#> Loss at epoch 68: 0.098083, lr: 0.01000
#> Loss at epoch 69: 0.096918, lr: 0.01000
#> Loss at epoch 70: 0.099659, lr: 0.01000
#> Loss at epoch 71: 0.094592, lr: 0.01000
#> Loss at epoch 72: 0.092785, lr: 0.01000
#> Loss at epoch 73: 0.090593, lr: 0.01000
#> Loss at epoch 74: 0.091643, lr: 0.01000
#> Loss at epoch 75: 0.092637, lr: 0.01000
#> Loss at epoch 76: 0.089657, lr: 0.01000
#> Loss at epoch 77: 0.086581, lr: 0.01000
#> Loss at epoch 78: 0.088828, lr: 0.01000
#> Loss at epoch 79: 0.087774, lr: 0.01000
#> Loss at epoch 80: 0.080636, lr: 0.01000
#> Loss at epoch 81: 0.082332, lr: 0.01000
#> Loss at epoch 82: 0.081213, lr: 0.01000
#> Loss at epoch 83: 0.080078, lr: 0.01000
#> Loss at epoch 84: 0.082587, lr: 0.01000
#> Loss at epoch 85: 0.081111, lr: 0.01000
#> Loss at epoch 86: 0.079289, lr: 0.01000
#> Loss at epoch 87: 0.077370, lr: 0.01000
#> Loss at epoch 88: 0.078495, lr: 0.01000
#> Loss at epoch 89: 0.077228, lr: 0.01000
#> Loss at epoch 90: 0.072742, lr: 0.01000
#> Loss at epoch 91: 0.074160, lr: 0.01000
#> Loss at epoch 92: 0.072535, lr: 0.01000
#> Loss at epoch 93: 0.072903, lr: 0.01000
#> Loss at epoch 94: 0.071393, lr: 0.01000
#> Loss at epoch 95: 0.074971, lr: 0.01000
#> Loss at epoch 96: 0.071612, lr: 0.01000
#> Loss at epoch 97: 0.068308, lr: 0.01000
#> Loss at epoch 98: 0.068272, lr: 0.01000
#> Loss at epoch 99: 0.075458, lr: 0.01000
#> Loss at epoch 100: 0.073320, lr: 0.01000
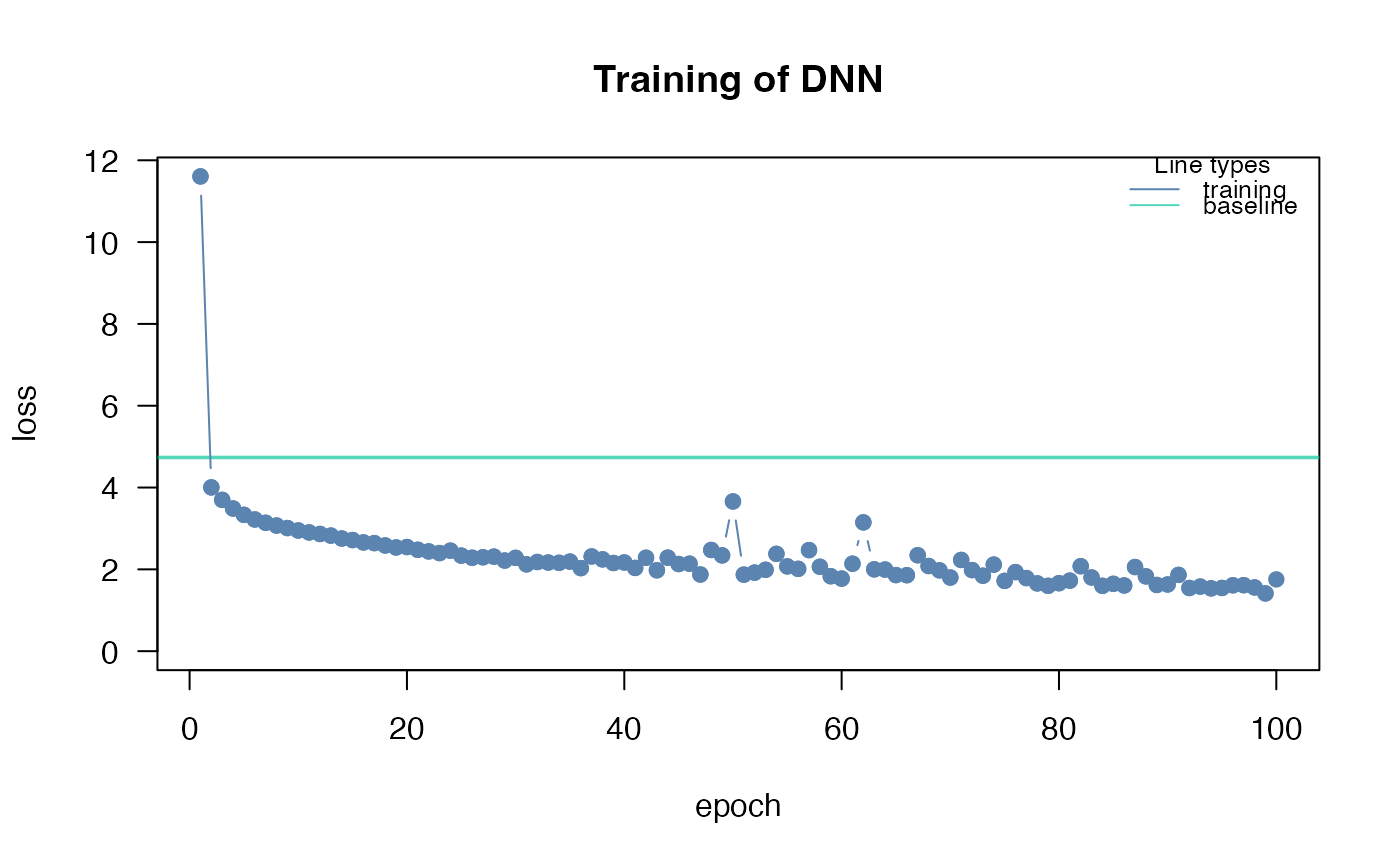
#> Loss at epoch 1: 1.029353, lr: 0.01000
#> Loss at epoch 2: 0.580236, lr: 0.01000
#> Loss at epoch 3: 0.549974, lr: 0.01000
#> Loss at epoch 4: 0.516203, lr: 0.01000
#> Loss at epoch 5: 0.492190, lr: 0.01000
#> Loss at epoch 6: 0.467423, lr: 0.01000
#> Loss at epoch 7: 0.445653, lr: 0.01000
#> Loss at epoch 8: 0.425039, lr: 0.01000
#> Loss at epoch 9: 0.405358, lr: 0.01000
#> Loss at epoch 10: 0.386309, lr: 0.01000
#> Loss at epoch 11: 0.372660, lr: 0.01000
#> Loss at epoch 12: 0.359912, lr: 0.01000
#> Loss at epoch 13: 0.347467, lr: 0.01000
#> Loss at epoch 14: 0.333965, lr: 0.01000
#> Loss at epoch 15: 0.324504, lr: 0.01000
#> Loss at epoch 16: 0.316904, lr: 0.01000
#> Loss at epoch 17: 0.304670, lr: 0.01000
#> Loss at epoch 18: 0.293441, lr: 0.01000
#> Loss at epoch 19: 0.287496, lr: 0.01000
#> Loss at epoch 20: 0.278483, lr: 0.01000
#> Loss at epoch 21: 0.273015, lr: 0.01000
#> Loss at epoch 22: 0.264038, lr: 0.01000
#> Loss at epoch 23: 0.259724, lr: 0.01000
#> Loss at epoch 24: 0.254735, lr: 0.01000
#> Loss at epoch 25: 0.243558, lr: 0.01000
#> Loss at epoch 26: 0.241815, lr: 0.01000
#> Loss at epoch 27: 0.232573, lr: 0.01000
#> Loss at epoch 28: 0.225291, lr: 0.01000
#> Loss at epoch 29: 0.219698, lr: 0.01000
#> Loss at epoch 30: 0.216967, lr: 0.01000
#> Loss at epoch 31: 0.213643, lr: 0.01000
#> Loss at epoch 32: 0.209031, lr: 0.01000
#> Loss at epoch 33: 0.201099, lr: 0.01000
#> Loss at epoch 34: 0.196401, lr: 0.01000
#> Loss at epoch 35: 0.190332, lr: 0.01000
#> Loss at epoch 36: 0.188689, lr: 0.01000
#> Loss at epoch 37: 0.180711, lr: 0.01000
#> Loss at epoch 38: 0.181188, lr: 0.01000
#> Loss at epoch 39: 0.169237, lr: 0.01000
#> Loss at epoch 40: 0.170794, lr: 0.01000
#> Loss at epoch 41: 0.164362, lr: 0.01000
#> Loss at epoch 42: 0.161676, lr: 0.01000
#> Loss at epoch 43: 0.158048, lr: 0.01000
#> Loss at epoch 44: 0.151875, lr: 0.01000
#> Loss at epoch 45: 0.151100, lr: 0.01000
#> Loss at epoch 46: 0.147166, lr: 0.01000
#> Loss at epoch 47: 0.142907, lr: 0.01000
#> Loss at epoch 48: 0.141146, lr: 0.01000
#> Loss at epoch 49: 0.136725, lr: 0.01000
#> Loss at epoch 50: 0.132671, lr: 0.01000
#> Loss at epoch 51: 0.130276, lr: 0.01000
#> Loss at epoch 52: 0.130272, lr: 0.01000
#> Loss at epoch 53: 0.128855, lr: 0.01000
#> Loss at epoch 54: 0.129522, lr: 0.01000
#> Loss at epoch 55: 0.121622, lr: 0.01000
#> Loss at epoch 56: 0.119577, lr: 0.01000
#> Loss at epoch 57: 0.115492, lr: 0.01000
#> Loss at epoch 58: 0.116751, lr: 0.01000
#> Loss at epoch 59: 0.118607, lr: 0.01000
#> Loss at epoch 60: 0.112974, lr: 0.01000
#> Loss at epoch 61: 0.105417, lr: 0.01000
#> Loss at epoch 62: 0.108555, lr: 0.01000
#> Loss at epoch 63: 0.108640, lr: 0.01000
#> Loss at epoch 64: 0.101279, lr: 0.01000
#> Loss at epoch 65: 0.103371, lr: 0.01000
#> Loss at epoch 66: 0.100340, lr: 0.01000
#> Loss at epoch 67: 0.098973, lr: 0.01000
#> Loss at epoch 68: 0.098083, lr: 0.01000
#> Loss at epoch 69: 0.096918, lr: 0.01000
#> Loss at epoch 70: 0.099659, lr: 0.01000
#> Loss at epoch 71: 0.094592, lr: 0.01000
#> Loss at epoch 72: 0.092785, lr: 0.01000
#> Loss at epoch 73: 0.090593, lr: 0.01000
#> Loss at epoch 74: 0.091643, lr: 0.01000
#> Loss at epoch 75: 0.092637, lr: 0.01000
#> Loss at epoch 76: 0.089657, lr: 0.01000
#> Loss at epoch 77: 0.086581, lr: 0.01000
#> Loss at epoch 78: 0.088828, lr: 0.01000
#> Loss at epoch 79: 0.087774, lr: 0.01000
#> Loss at epoch 80: 0.080636, lr: 0.01000
#> Loss at epoch 81: 0.082332, lr: 0.01000
#> Loss at epoch 82: 0.081213, lr: 0.01000
#> Loss at epoch 83: 0.080078, lr: 0.01000
#> Loss at epoch 84: 0.082587, lr: 0.01000
#> Loss at epoch 85: 0.081111, lr: 0.01000
#> Loss at epoch 86: 0.079289, lr: 0.01000
#> Loss at epoch 87: 0.077370, lr: 0.01000
#> Loss at epoch 88: 0.078495, lr: 0.01000
#> Loss at epoch 89: 0.077228, lr: 0.01000
#> Loss at epoch 90: 0.072742, lr: 0.01000
#> Loss at epoch 91: 0.074160, lr: 0.01000
#> Loss at epoch 92: 0.072535, lr: 0.01000
#> Loss at epoch 93: 0.072903, lr: 0.01000
#> Loss at epoch 94: 0.071393, lr: 0.01000
#> Loss at epoch 95: 0.074971, lr: 0.01000
#> Loss at epoch 96: 0.071612, lr: 0.01000
#> Loss at epoch 97: 0.068308, lr: 0.01000
#> Loss at epoch 98: 0.068272, lr: 0.01000
#> Loss at epoch 99: 0.075458, lr: 0.01000
#> Loss at epoch 100: 0.073320, lr: 0.01000
#> Loss at epoch 1: 1.029353, lr: 0.01000
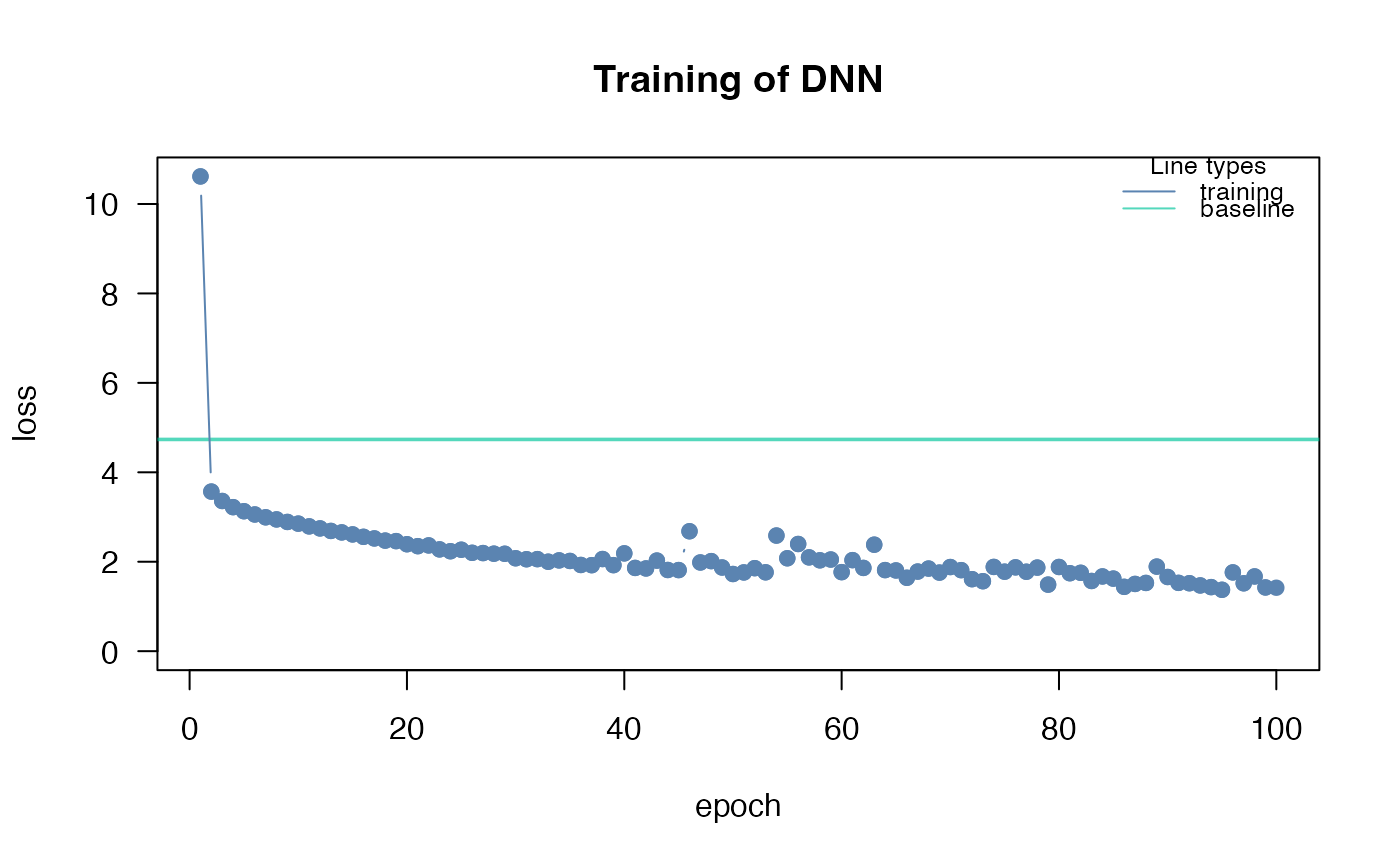 #> Loss at epoch 2: 0.838056, lr: 0.01000
#> Loss at epoch 3: 0.736363, lr: 0.01000
#> Loss at epoch 4: 0.665682, lr: 0.01000
#> Loss at epoch 5: 0.596405, lr: 0.01000
#> Loss at epoch 6: 0.553778, lr: 0.01000
#> Loss at epoch 7: 0.517172, lr: 0.01000
#> Loss at epoch 8: 0.510965, lr: 0.01000
#> Loss at epoch 9: 0.454185, lr: 0.01000
#> Loss at epoch 10: 0.444283, lr: 0.01000
#> Loss at epoch 11: 0.410581, lr: 0.01000
#> Loss at epoch 12: 0.395968, lr: 0.01000
#> Loss at epoch 13: 0.385857, lr: 0.01000
#> Loss at epoch 14: 0.376048, lr: 0.01000
#> Loss at epoch 15: 0.352194, lr: 0.01000
#> Loss at epoch 16: 0.338680, lr: 0.01000
#> Loss at epoch 17: 0.325352, lr: 0.01000
#> Loss at epoch 18: 0.315521, lr: 0.01000
#> Loss at epoch 19: 0.312051, lr: 0.01000
#> Loss at epoch 20: 0.295578, lr: 0.01000
#> Loss at epoch 21: 0.284522, lr: 0.01000
#> Loss at epoch 22: 0.275860, lr: 0.01000
#> Loss at epoch 23: 0.281111, lr: 0.01000
#> Loss at epoch 24: 0.257511, lr: 0.01000
#> Loss at epoch 25: 0.272087, lr: 0.01000
#> Loss at epoch 26: 0.231601, lr: 0.01000
#> Loss at epoch 27: 0.221238, lr: 0.01000
#> Loss at epoch 28: 0.238053, lr: 0.01000
#> Loss at epoch 29: 0.246936, lr: 0.01000
#> Loss at epoch 30: 0.224995, lr: 0.01000
#> Loss at epoch 31: 0.210830, lr: 0.01000
#> Loss at epoch 32: 0.214294, lr: 0.01000
#> Loss at epoch 33: 0.216633, lr: 0.01000
#> Loss at epoch 34: 0.197873, lr: 0.01000
#> Loss at epoch 35: 0.185298, lr: 0.01000
#> Loss at epoch 36: 0.181255, lr: 0.01000
#> Loss at epoch 37: 0.181786, lr: 0.01000
#> Loss at epoch 38: 0.164843, lr: 0.01000
#> Loss at epoch 39: 0.180574, lr: 0.01000
#> Loss at epoch 40: 0.164188, lr: 0.01000
#> Loss at epoch 41: 0.155880, lr: 0.01000
#> Loss at epoch 42: 0.158921, lr: 0.01000
#> Loss at epoch 43: 0.149166, lr: 0.01000
#> Loss at epoch 44: 0.149103, lr: 0.01000
#> Loss at epoch 45: 0.150007, lr: 0.01000
#> Loss at epoch 46: 0.148908, lr: 0.01000
#> Loss at epoch 47: 0.137504, lr: 0.01000
#> Loss at epoch 48: 0.148899, lr: 0.01000
#> Loss at epoch 49: 0.138947, lr: 0.01000
#> Loss at epoch 50: 0.125745, lr: 0.01000
#> Loss at epoch 51: 0.129502, lr: 0.01000
#> Loss at epoch 52: 0.120199, lr: 0.01000
#> Loss at epoch 53: 0.121725, lr: 0.01000
#> Loss at epoch 54: 0.123944, lr: 0.01000
#> Loss at epoch 55: 0.118878, lr: 0.01000
#> Loss at epoch 56: 0.115712, lr: 0.01000
#> Loss at epoch 57: 0.114687, lr: 0.01000
#> Loss at epoch 58: 0.106719, lr: 0.01000
#> Loss at epoch 59: 0.112906, lr: 0.01000
#> Loss at epoch 60: 0.104644, lr: 0.01000
#> Loss at epoch 61: 0.116849, lr: 0.01000
#> Loss at epoch 62: 0.135903, lr: 0.01000
#> Loss at epoch 63: 0.112682, lr: 0.01000
#> Loss at epoch 64: 0.112904, lr: 0.01000
#> Loss at epoch 65: 0.102428, lr: 0.01000
#> Loss at epoch 66: 0.105639, lr: 0.01000
#> Loss at epoch 67: 0.096896, lr: 0.01000
#> Loss at epoch 68: 0.115266, lr: 0.01000
#> Loss at epoch 69: 0.101151, lr: 0.01000
#> Loss at epoch 70: 0.098566, lr: 0.01000
#> Loss at epoch 71: 0.096959, lr: 0.01000
#> Loss at epoch 72: 0.099351, lr: 0.01000
#> Loss at epoch 73: 0.105310, lr: 0.01000
#> Loss at epoch 74: 0.098299, lr: 0.01000
#> Loss at epoch 75: 0.099592, lr: 0.01000
#> Loss at epoch 76: 0.098473, lr: 0.01000
#> Loss at epoch 77: 0.096547, lr: 0.01000
#> Loss at epoch 78: 0.091812, lr: 0.01000
#> Loss at epoch 79: 0.088663, lr: 0.01000
#> Loss at epoch 80: 0.098265, lr: 0.01000
#> Loss at epoch 81: 0.097573, lr: 0.01000
#> Loss at epoch 82: 0.103566, lr: 0.01000
#> Loss at epoch 83: 0.083291, lr: 0.01000
#> Loss at epoch 84: 0.084916, lr: 0.01000
#> Loss at epoch 85: 0.083162, lr: 0.01000
#> Loss at epoch 86: 0.088358, lr: 0.01000
#> Loss at epoch 87: 0.076779, lr: 0.01000
#> Loss at epoch 88: 0.083051, lr: 0.01000
#> Loss at epoch 89: 0.074115, lr: 0.01000
#> Loss at epoch 90: 0.079659, lr: 0.01000
#> Loss at epoch 91: 0.082169, lr: 0.01000
#> Loss at epoch 92: 0.075564, lr: 0.01000
#> Loss at epoch 93: 0.084325, lr: 0.01000
#> Loss at epoch 94: 0.083941, lr: 0.01000
#> Loss at epoch 95: 0.074055, lr: 0.01000
#> Loss at epoch 96: 0.077409, lr: 0.01000
#> Loss at epoch 97: 0.078532, lr: 0.01000
#> Loss at epoch 98: 0.089807, lr: 0.01000
#> Loss at epoch 99: 0.081542, lr: 0.01000
#> Loss at epoch 100: 0.073402, lr: 0.01000
#> Loss at epoch 1: 4.050235, lr: 0.01000
#> Loss at epoch 2: 0.838056, lr: 0.01000
#> Loss at epoch 3: 0.736363, lr: 0.01000
#> Loss at epoch 4: 0.665682, lr: 0.01000
#> Loss at epoch 5: 0.596405, lr: 0.01000
#> Loss at epoch 6: 0.553778, lr: 0.01000
#> Loss at epoch 7: 0.517172, lr: 0.01000
#> Loss at epoch 8: 0.510965, lr: 0.01000
#> Loss at epoch 9: 0.454185, lr: 0.01000
#> Loss at epoch 10: 0.444283, lr: 0.01000
#> Loss at epoch 11: 0.410581, lr: 0.01000
#> Loss at epoch 12: 0.395968, lr: 0.01000
#> Loss at epoch 13: 0.385857, lr: 0.01000
#> Loss at epoch 14: 0.376048, lr: 0.01000
#> Loss at epoch 15: 0.352194, lr: 0.01000
#> Loss at epoch 16: 0.338680, lr: 0.01000
#> Loss at epoch 17: 0.325352, lr: 0.01000
#> Loss at epoch 18: 0.315521, lr: 0.01000
#> Loss at epoch 19: 0.312051, lr: 0.01000
#> Loss at epoch 20: 0.295578, lr: 0.01000
#> Loss at epoch 21: 0.284522, lr: 0.01000
#> Loss at epoch 22: 0.275860, lr: 0.01000
#> Loss at epoch 23: 0.281111, lr: 0.01000
#> Loss at epoch 24: 0.257511, lr: 0.01000
#> Loss at epoch 25: 0.272087, lr: 0.01000
#> Loss at epoch 26: 0.231601, lr: 0.01000
#> Loss at epoch 27: 0.221238, lr: 0.01000
#> Loss at epoch 28: 0.238053, lr: 0.01000
#> Loss at epoch 29: 0.246936, lr: 0.01000
#> Loss at epoch 30: 0.224995, lr: 0.01000
#> Loss at epoch 31: 0.210830, lr: 0.01000
#> Loss at epoch 32: 0.214294, lr: 0.01000
#> Loss at epoch 33: 0.216633, lr: 0.01000
#> Loss at epoch 34: 0.197873, lr: 0.01000
#> Loss at epoch 35: 0.185298, lr: 0.01000
#> Loss at epoch 36: 0.181255, lr: 0.01000
#> Loss at epoch 37: 0.181786, lr: 0.01000
#> Loss at epoch 38: 0.164843, lr: 0.01000
#> Loss at epoch 39: 0.180574, lr: 0.01000
#> Loss at epoch 40: 0.164188, lr: 0.01000
#> Loss at epoch 41: 0.155880, lr: 0.01000
#> Loss at epoch 42: 0.158921, lr: 0.01000
#> Loss at epoch 43: 0.149166, lr: 0.01000
#> Loss at epoch 44: 0.149103, lr: 0.01000
#> Loss at epoch 45: 0.150007, lr: 0.01000
#> Loss at epoch 46: 0.148908, lr: 0.01000
#> Loss at epoch 47: 0.137504, lr: 0.01000
#> Loss at epoch 48: 0.148899, lr: 0.01000
#> Loss at epoch 49: 0.138947, lr: 0.01000
#> Loss at epoch 50: 0.125745, lr: 0.01000
#> Loss at epoch 51: 0.129502, lr: 0.01000
#> Loss at epoch 52: 0.120199, lr: 0.01000
#> Loss at epoch 53: 0.121725, lr: 0.01000
#> Loss at epoch 54: 0.123944, lr: 0.01000
#> Loss at epoch 55: 0.118878, lr: 0.01000
#> Loss at epoch 56: 0.115712, lr: 0.01000
#> Loss at epoch 57: 0.114687, lr: 0.01000
#> Loss at epoch 58: 0.106719, lr: 0.01000
#> Loss at epoch 59: 0.112906, lr: 0.01000
#> Loss at epoch 60: 0.104644, lr: 0.01000
#> Loss at epoch 61: 0.116849, lr: 0.01000
#> Loss at epoch 62: 0.135903, lr: 0.01000
#> Loss at epoch 63: 0.112682, lr: 0.01000
#> Loss at epoch 64: 0.112904, lr: 0.01000
#> Loss at epoch 65: 0.102428, lr: 0.01000
#> Loss at epoch 66: 0.105639, lr: 0.01000
#> Loss at epoch 67: 0.096896, lr: 0.01000
#> Loss at epoch 68: 0.115266, lr: 0.01000
#> Loss at epoch 69: 0.101151, lr: 0.01000
#> Loss at epoch 70: 0.098566, lr: 0.01000
#> Loss at epoch 71: 0.096959, lr: 0.01000
#> Loss at epoch 72: 0.099351, lr: 0.01000
#> Loss at epoch 73: 0.105310, lr: 0.01000
#> Loss at epoch 74: 0.098299, lr: 0.01000
#> Loss at epoch 75: 0.099592, lr: 0.01000
#> Loss at epoch 76: 0.098473, lr: 0.01000
#> Loss at epoch 77: 0.096547, lr: 0.01000
#> Loss at epoch 78: 0.091812, lr: 0.01000
#> Loss at epoch 79: 0.088663, lr: 0.01000
#> Loss at epoch 80: 0.098265, lr: 0.01000
#> Loss at epoch 81: 0.097573, lr: 0.01000
#> Loss at epoch 82: 0.103566, lr: 0.01000
#> Loss at epoch 83: 0.083291, lr: 0.01000
#> Loss at epoch 84: 0.084916, lr: 0.01000
#> Loss at epoch 85: 0.083162, lr: 0.01000
#> Loss at epoch 86: 0.088358, lr: 0.01000
#> Loss at epoch 87: 0.076779, lr: 0.01000
#> Loss at epoch 88: 0.083051, lr: 0.01000
#> Loss at epoch 89: 0.074115, lr: 0.01000
#> Loss at epoch 90: 0.079659, lr: 0.01000
#> Loss at epoch 91: 0.082169, lr: 0.01000
#> Loss at epoch 92: 0.075564, lr: 0.01000
#> Loss at epoch 93: 0.084325, lr: 0.01000
#> Loss at epoch 94: 0.083941, lr: 0.01000
#> Loss at epoch 95: 0.074055, lr: 0.01000
#> Loss at epoch 96: 0.077409, lr: 0.01000
#> Loss at epoch 97: 0.078532, lr: 0.01000
#> Loss at epoch 98: 0.089807, lr: 0.01000
#> Loss at epoch 99: 0.081542, lr: 0.01000
#> Loss at epoch 100: 0.073402, lr: 0.01000
#> Loss at epoch 1: 4.050235, lr: 0.01000
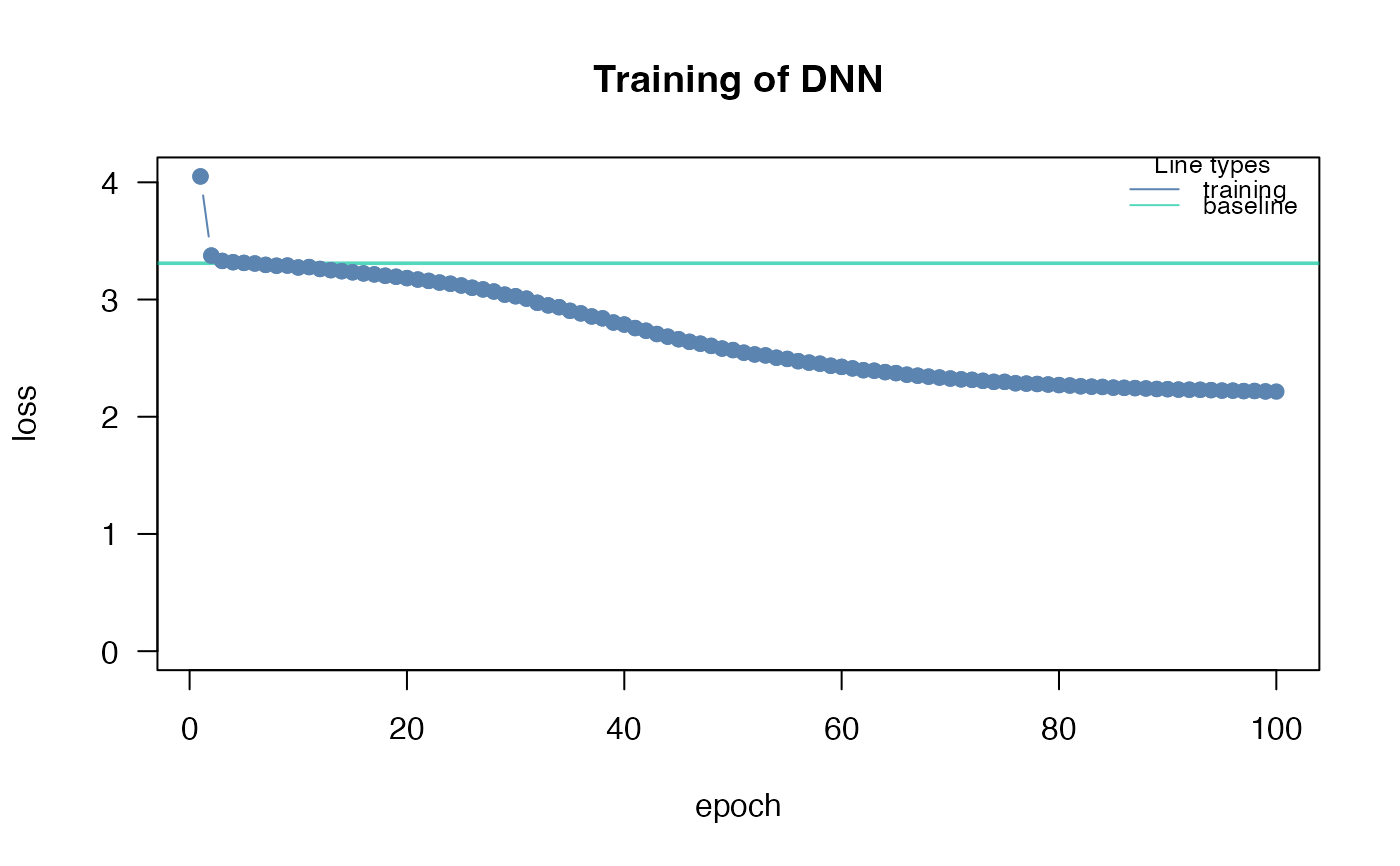 #> Loss at epoch 2: 3.375148, lr: 0.01000
#> Loss at epoch 3: 3.329331, lr: 0.01000
#> Loss at epoch 4: 3.318493, lr: 0.01000
#> Loss at epoch 5: 3.312524, lr: 0.01000
#> Loss at epoch 6: 3.307514, lr: 0.01000
#> Loss at epoch 7: 3.295704, lr: 0.01000
#> Loss at epoch 8: 3.288458, lr: 0.01000
#> Loss at epoch 9: 3.289731, lr: 0.01000
#> Loss at epoch 10: 3.273467, lr: 0.01000
#> Loss at epoch 11: 3.277107, lr: 0.01000
#> Loss at epoch 12: 3.260709, lr: 0.01000
#> Loss at epoch 13: 3.250570, lr: 0.01000
#> Loss at epoch 14: 3.241755, lr: 0.01000
#> Loss at epoch 15: 3.232278, lr: 0.01000
#> Loss at epoch 16: 3.222933, lr: 0.01000
#> Loss at epoch 17: 3.214489, lr: 0.01000
#> Loss at epoch 18: 3.202994, lr: 0.01000
#> Loss at epoch 19: 3.194378, lr: 0.01000
#> Loss at epoch 20: 3.182967, lr: 0.01000
#> Loss at epoch 21: 3.170651, lr: 0.01000
#> Loss at epoch 22: 3.159124, lr: 0.01000
#> Loss at epoch 23: 3.144849, lr: 0.01000
#> Loss at epoch 24: 3.134571, lr: 0.01000
#> Loss at epoch 25: 3.119773, lr: 0.01000
#> Loss at epoch 26: 3.100516, lr: 0.01000
#> Loss at epoch 27: 3.086322, lr: 0.01000
#> Loss at epoch 28: 3.068383, lr: 0.01000
#> Loss at epoch 29: 3.041739, lr: 0.01000
#> Loss at epoch 30: 3.027909, lr: 0.01000
#> Loss at epoch 31: 3.007568, lr: 0.01000
#> Loss at epoch 32: 2.972370, lr: 0.01000
#> Loss at epoch 33: 2.950035, lr: 0.01000
#> Loss at epoch 34: 2.934669, lr: 0.01000
#> Loss at epoch 35: 2.903744, lr: 0.01000
#> Loss at epoch 36: 2.881857, lr: 0.01000
#> Loss at epoch 37: 2.855614, lr: 0.01000
#> Loss at epoch 38: 2.839620, lr: 0.01000
#> Loss at epoch 39: 2.804028, lr: 0.01000
#> Loss at epoch 40: 2.786639, lr: 0.01000
#> Loss at epoch 41: 2.756574, lr: 0.01000
#> Loss at epoch 42: 2.733724, lr: 0.01000
#> Loss at epoch 43: 2.705919, lr: 0.01000
#> Loss at epoch 44: 2.683190, lr: 0.01000
#> Loss at epoch 45: 2.661252, lr: 0.01000
#> Loss at epoch 46: 2.639226, lr: 0.01000
#> Loss at epoch 47: 2.623245, lr: 0.01000
#> Loss at epoch 48: 2.604573, lr: 0.01000
#> Loss at epoch 49: 2.581663, lr: 0.01000
#> Loss at epoch 50: 2.568873, lr: 0.01000
#> Loss at epoch 51: 2.546475, lr: 0.01000
#> Loss at epoch 52: 2.531580, lr: 0.01000
#> Loss at epoch 53: 2.523293, lr: 0.01000
#> Loss at epoch 54: 2.503576, lr: 0.01000
#> Loss at epoch 55: 2.493250, lr: 0.01000
#> Loss at epoch 56: 2.474042, lr: 0.01000
#> Loss at epoch 57: 2.461848, lr: 0.01000
#> Loss at epoch 58: 2.452574, lr: 0.01000
#> Loss at epoch 59: 2.434963, lr: 0.01000
#> Loss at epoch 60: 2.425406, lr: 0.01000
#> Loss at epoch 61: 2.412445, lr: 0.01000
#> Loss at epoch 62: 2.397073, lr: 0.01000
#> Loss at epoch 63: 2.392707, lr: 0.01000
#> Loss at epoch 64: 2.380811, lr: 0.01000
#> Loss at epoch 65: 2.372324, lr: 0.01000
#> Loss at epoch 66: 2.358699, lr: 0.01000
#> Loss at epoch 67: 2.350289, lr: 0.01000
#> Loss at epoch 68: 2.342029, lr: 0.01000
#> Loss at epoch 69: 2.334479, lr: 0.01000
#> Loss at epoch 70: 2.325935, lr: 0.01000
#> Loss at epoch 71: 2.319037, lr: 0.01000
#> Loss at epoch 72: 2.314725, lr: 0.01000
#> Loss at epoch 73: 2.306465, lr: 0.01000
#> Loss at epoch 74: 2.297722, lr: 0.01000
#> Loss at epoch 75: 2.297563, lr: 0.01000
#> Loss at epoch 76: 2.285706, lr: 0.01000
#> Loss at epoch 77: 2.282699, lr: 0.01000
#> Loss at epoch 78: 2.279500, lr: 0.01000
#> Loss at epoch 79: 2.275048, lr: 0.01000
#> Loss at epoch 80: 2.270183, lr: 0.01000
#> Loss at epoch 81: 2.266580, lr: 0.01000
#> Loss at epoch 82: 2.259874, lr: 0.01000
#> Loss at epoch 83: 2.256623, lr: 0.01000
#> Loss at epoch 84: 2.254239, lr: 0.01000
#> Loss at epoch 85: 2.248330, lr: 0.01000
#> Loss at epoch 86: 2.246702, lr: 0.01000
#> Loss at epoch 87: 2.244490, lr: 0.01000
#> Loss at epoch 88: 2.241368, lr: 0.01000
#> Loss at epoch 89: 2.236798, lr: 0.01000
#> Loss at epoch 90: 2.235200, lr: 0.01000
#> Loss at epoch 91: 2.231554, lr: 0.01000
#> Loss at epoch 92: 2.230841, lr: 0.01000
#> Loss at epoch 93: 2.230056, lr: 0.01000
#> Loss at epoch 94: 2.227161, lr: 0.01000
#> Loss at epoch 95: 2.223092, lr: 0.01000
#> Loss at epoch 96: 2.222676, lr: 0.01000
#> Loss at epoch 97: 2.218990, lr: 0.01000
#> Loss at epoch 98: 2.219755, lr: 0.01000
#> Loss at epoch 99: 2.216133, lr: 0.01000
#> Loss at epoch 100: 2.214781, lr: 0.01000
#> [,1] [,2]
#> [1,] 5 2
#> [2,] 4 2
#> [3,] 10 2
#> [4,] 15 2
#> Starting hyperparameter tuning...
#> Fitting final model...
#> # A tibble: 10 × 6
#> steps test train models hidden lr
#> <int> <dbl> <dbl> <lgl> <list> <dbl>
#> 1 1 53.8 0 NA <dbl [2]> 0.0168
#> 2 2 60.5 0 NA <dbl [2]> 0.0722
#> 3 3 26.1 0 NA <dbl [2]> 0.0862
#> 4 4 57.5 0 NA <dbl [2]> 0.0869
#> 5 5 31.9 0 NA <dbl [2]> 0.0225
#> 6 6 29.4 0 NA <dbl [2]> 0.0625
#> 7 7 30.5 0 NA <dbl [2]> 0.0960
#> 8 8 43.0 0 NA <dbl [2]> 0.0654
#> 9 9 45.9 0 NA <dbl [2]> 0.0342
#> 10 10 83.4 0 NA <dbl [2]> 0.00692
#> Loss at epoch 2: 3.375148, lr: 0.01000
#> Loss at epoch 3: 3.329331, lr: 0.01000
#> Loss at epoch 4: 3.318493, lr: 0.01000
#> Loss at epoch 5: 3.312524, lr: 0.01000
#> Loss at epoch 6: 3.307514, lr: 0.01000
#> Loss at epoch 7: 3.295704, lr: 0.01000
#> Loss at epoch 8: 3.288458, lr: 0.01000
#> Loss at epoch 9: 3.289731, lr: 0.01000
#> Loss at epoch 10: 3.273467, lr: 0.01000
#> Loss at epoch 11: 3.277107, lr: 0.01000
#> Loss at epoch 12: 3.260709, lr: 0.01000
#> Loss at epoch 13: 3.250570, lr: 0.01000
#> Loss at epoch 14: 3.241755, lr: 0.01000
#> Loss at epoch 15: 3.232278, lr: 0.01000
#> Loss at epoch 16: 3.222933, lr: 0.01000
#> Loss at epoch 17: 3.214489, lr: 0.01000
#> Loss at epoch 18: 3.202994, lr: 0.01000
#> Loss at epoch 19: 3.194378, lr: 0.01000
#> Loss at epoch 20: 3.182967, lr: 0.01000
#> Loss at epoch 21: 3.170651, lr: 0.01000
#> Loss at epoch 22: 3.159124, lr: 0.01000
#> Loss at epoch 23: 3.144849, lr: 0.01000
#> Loss at epoch 24: 3.134571, lr: 0.01000
#> Loss at epoch 25: 3.119773, lr: 0.01000
#> Loss at epoch 26: 3.100516, lr: 0.01000
#> Loss at epoch 27: 3.086322, lr: 0.01000
#> Loss at epoch 28: 3.068383, lr: 0.01000
#> Loss at epoch 29: 3.041739, lr: 0.01000
#> Loss at epoch 30: 3.027909, lr: 0.01000
#> Loss at epoch 31: 3.007568, lr: 0.01000
#> Loss at epoch 32: 2.972370, lr: 0.01000
#> Loss at epoch 33: 2.950035, lr: 0.01000
#> Loss at epoch 34: 2.934669, lr: 0.01000
#> Loss at epoch 35: 2.903744, lr: 0.01000
#> Loss at epoch 36: 2.881857, lr: 0.01000
#> Loss at epoch 37: 2.855614, lr: 0.01000
#> Loss at epoch 38: 2.839620, lr: 0.01000
#> Loss at epoch 39: 2.804028, lr: 0.01000
#> Loss at epoch 40: 2.786639, lr: 0.01000
#> Loss at epoch 41: 2.756574, lr: 0.01000
#> Loss at epoch 42: 2.733724, lr: 0.01000
#> Loss at epoch 43: 2.705919, lr: 0.01000
#> Loss at epoch 44: 2.683190, lr: 0.01000
#> Loss at epoch 45: 2.661252, lr: 0.01000
#> Loss at epoch 46: 2.639226, lr: 0.01000
#> Loss at epoch 47: 2.623245, lr: 0.01000
#> Loss at epoch 48: 2.604573, lr: 0.01000
#> Loss at epoch 49: 2.581663, lr: 0.01000
#> Loss at epoch 50: 2.568873, lr: 0.01000
#> Loss at epoch 51: 2.546475, lr: 0.01000
#> Loss at epoch 52: 2.531580, lr: 0.01000
#> Loss at epoch 53: 2.523293, lr: 0.01000
#> Loss at epoch 54: 2.503576, lr: 0.01000
#> Loss at epoch 55: 2.493250, lr: 0.01000
#> Loss at epoch 56: 2.474042, lr: 0.01000
#> Loss at epoch 57: 2.461848, lr: 0.01000
#> Loss at epoch 58: 2.452574, lr: 0.01000
#> Loss at epoch 59: 2.434963, lr: 0.01000
#> Loss at epoch 60: 2.425406, lr: 0.01000
#> Loss at epoch 61: 2.412445, lr: 0.01000
#> Loss at epoch 62: 2.397073, lr: 0.01000
#> Loss at epoch 63: 2.392707, lr: 0.01000
#> Loss at epoch 64: 2.380811, lr: 0.01000
#> Loss at epoch 65: 2.372324, lr: 0.01000
#> Loss at epoch 66: 2.358699, lr: 0.01000
#> Loss at epoch 67: 2.350289, lr: 0.01000
#> Loss at epoch 68: 2.342029, lr: 0.01000
#> Loss at epoch 69: 2.334479, lr: 0.01000
#> Loss at epoch 70: 2.325935, lr: 0.01000
#> Loss at epoch 71: 2.319037, lr: 0.01000
#> Loss at epoch 72: 2.314725, lr: 0.01000
#> Loss at epoch 73: 2.306465, lr: 0.01000
#> Loss at epoch 74: 2.297722, lr: 0.01000
#> Loss at epoch 75: 2.297563, lr: 0.01000
#> Loss at epoch 76: 2.285706, lr: 0.01000
#> Loss at epoch 77: 2.282699, lr: 0.01000
#> Loss at epoch 78: 2.279500, lr: 0.01000
#> Loss at epoch 79: 2.275048, lr: 0.01000
#> Loss at epoch 80: 2.270183, lr: 0.01000
#> Loss at epoch 81: 2.266580, lr: 0.01000
#> Loss at epoch 82: 2.259874, lr: 0.01000
#> Loss at epoch 83: 2.256623, lr: 0.01000
#> Loss at epoch 84: 2.254239, lr: 0.01000
#> Loss at epoch 85: 2.248330, lr: 0.01000
#> Loss at epoch 86: 2.246702, lr: 0.01000
#> Loss at epoch 87: 2.244490, lr: 0.01000
#> Loss at epoch 88: 2.241368, lr: 0.01000
#> Loss at epoch 89: 2.236798, lr: 0.01000
#> Loss at epoch 90: 2.235200, lr: 0.01000
#> Loss at epoch 91: 2.231554, lr: 0.01000
#> Loss at epoch 92: 2.230841, lr: 0.01000
#> Loss at epoch 93: 2.230056, lr: 0.01000
#> Loss at epoch 94: 2.227161, lr: 0.01000
#> Loss at epoch 95: 2.223092, lr: 0.01000
#> Loss at epoch 96: 2.222676, lr: 0.01000
#> Loss at epoch 97: 2.218990, lr: 0.01000
#> Loss at epoch 98: 2.219755, lr: 0.01000
#> Loss at epoch 99: 2.216133, lr: 0.01000
#> Loss at epoch 100: 2.214781, lr: 0.01000
#> [,1] [,2]
#> [1,] 5 2
#> [2,] 4 2
#> [3,] 10 2
#> [4,] 15 2
#> Starting hyperparameter tuning...
#> Fitting final model...
#> # A tibble: 10 × 6
#> steps test train models hidden lr
#> <int> <dbl> <dbl> <lgl> <list> <dbl>
#> 1 1 53.8 0 NA <dbl [2]> 0.0168
#> 2 2 60.5 0 NA <dbl [2]> 0.0722
#> 3 3 26.1 0 NA <dbl [2]> 0.0862
#> 4 4 57.5 0 NA <dbl [2]> 0.0869
#> 5 5 31.9 0 NA <dbl [2]> 0.0225
#> 6 6 29.4 0 NA <dbl [2]> 0.0625
#> 7 7 30.5 0 NA <dbl [2]> 0.0960
#> 8 8 43.0 0 NA <dbl [2]> 0.0654
#> 9 9 45.9 0 NA <dbl [2]> 0.0342
#> 10 10 83.4 0 NA <dbl [2]> 0.00692

 #> [,1] [,2] [,3]
#> [1,] 0.32808802 0.03195751 0.07836789
#> [2,] 0.03195751 0.15858485 0.02492121
#> [3,] 0.07836789 0.02492121 0.23315211
# }
#> [,1] [,2] [,3]
#> [1,] 0.32808802 0.03195751 0.07836789
#> [2,] 0.03195751 0.15858485 0.02492121
#> [3,] 0.07836789 0.02492121 0.23315211
# }